cjwbw/pix2struct 📝🖼️❓ → 📝
Performance
2.6sTypical run time
6.1KTotal runs
About
Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding
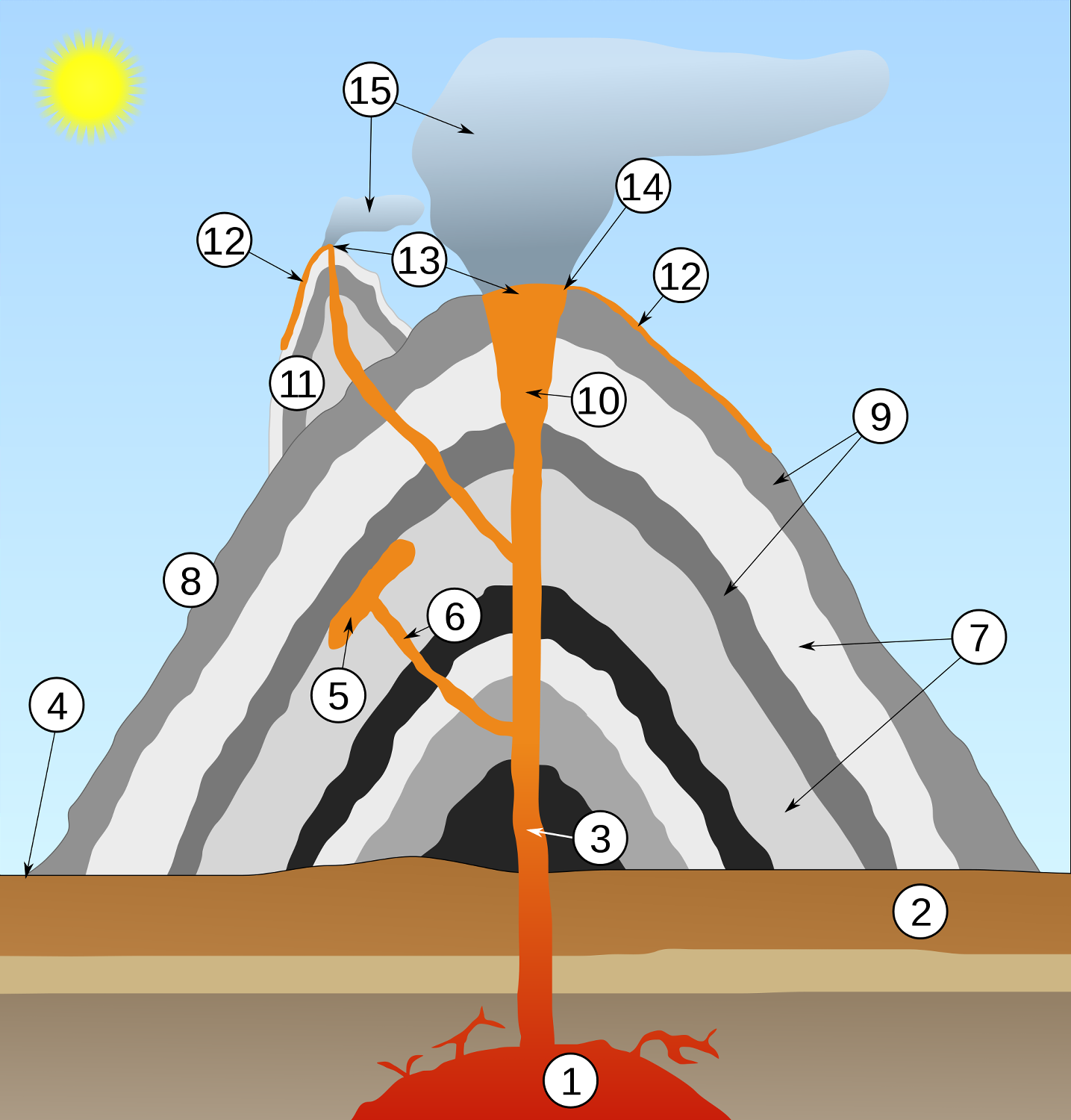
Example Output
Output
ash cloud
Performance Metrics
2.62s
Prediction Time
2.72s
Total Time
All Input Parameters
{
"text": "What does the label 15 represent? (1) lava (2) core (3) tunnel (4) ash cloud",
"image": "https://replicate.delivery/pbxt/IYTqGFhESyTxWX9AgFABgMdfStkVTkDZrNGCqhS6VCijFLgj/ai2d-demo.jpg",
"model_name": "ai2d"
}
Input Parameters
- text (required)
- Input text.
- image (required)
- Input Image.
- model_name
- Choose a model.
Output Schema
Output
Example Execution Logs
Adding prompt for VQA model: 'What does the label 15 represent? (1) lava (2) core (3) tunnel (4) ash cloud' A decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.
Version Details
- Version ID
e32d77481424b47e7959836638b62082d8528b0c66a3a30eedca3970aaf786e7- Version Created
- March 28, 2023