🤖 Model

lucataco/nomic-embed-text-v1
Convert text into vector embeddings for semantic search, retrieval-augmented generation, clustering, and classification....
Found 61 models (showing 1-20)
Convert text into vector embeddings for semantic search, retrieval-augmented generation, clustering, and classification....

Embed text into 1024-dimensional vectors for semantic search, dense retrieval, and RAG pipelines. Takes a text prompt an...

Convert text or images into 768-dimensional vector embeddings that capture semantic meaning. Uses OpenAI's CLIP model to...

Embed text into dense vectors for semantic search, retrieval/reranking, clustering, classification, recommendations, and...

Generate multilingual text embeddings for semantic search, retrieval, and clustering. Takes one or more texts as input a...

Convert text into dense vector embeddings for semantic search and retrieval. Generate sentence and paragraph embeddings...
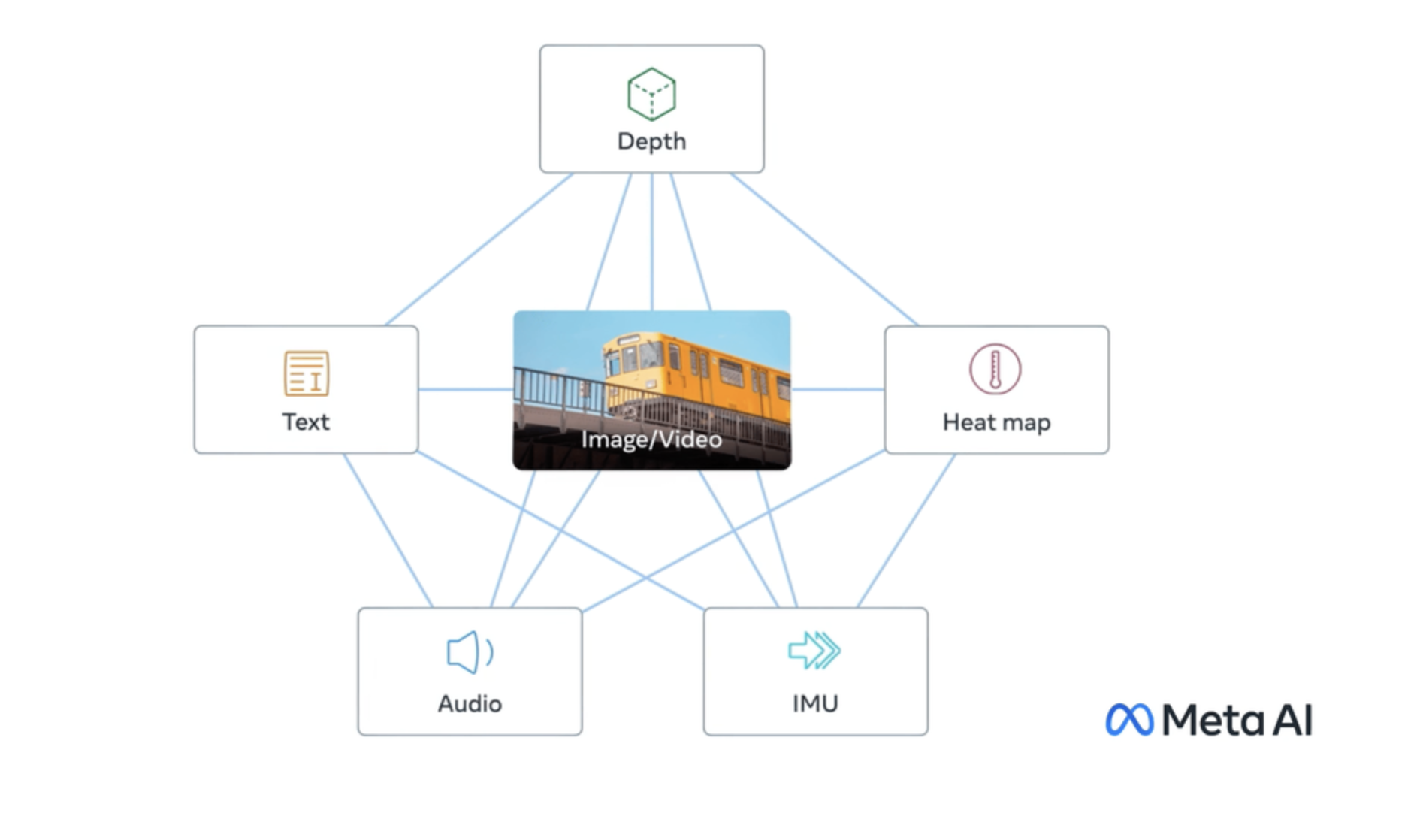
Generate shared embeddings for text, images, and audio for cross-modal retrieval and similarity search. Accepts a text s...
Generate dense embeddings for text queries and document screenshots to power document, PDF, webpage, and slide retrieval...

Convert text into 128–768-dimensional embeddings for semantic search, retrieval-augmented generation (RAG), classificati...
Convert text into dense vector embeddings for semantic search, information retrieval, semantic textual similarity, reran...

Convert English text into dense vector embeddings. Accepts lists of text strings and returns normalized embeddings for s...

Generate query embeddings from short English text for passage retrieval and semantic search. Accepts an array of query s...
Generate text embeddings from one or more text strings. Accept up to five text inputs and return dense vector embeddings...

Generate multilingual text embeddings for semantic search, similarity, and retrieval. Accepts a list of texts and return...
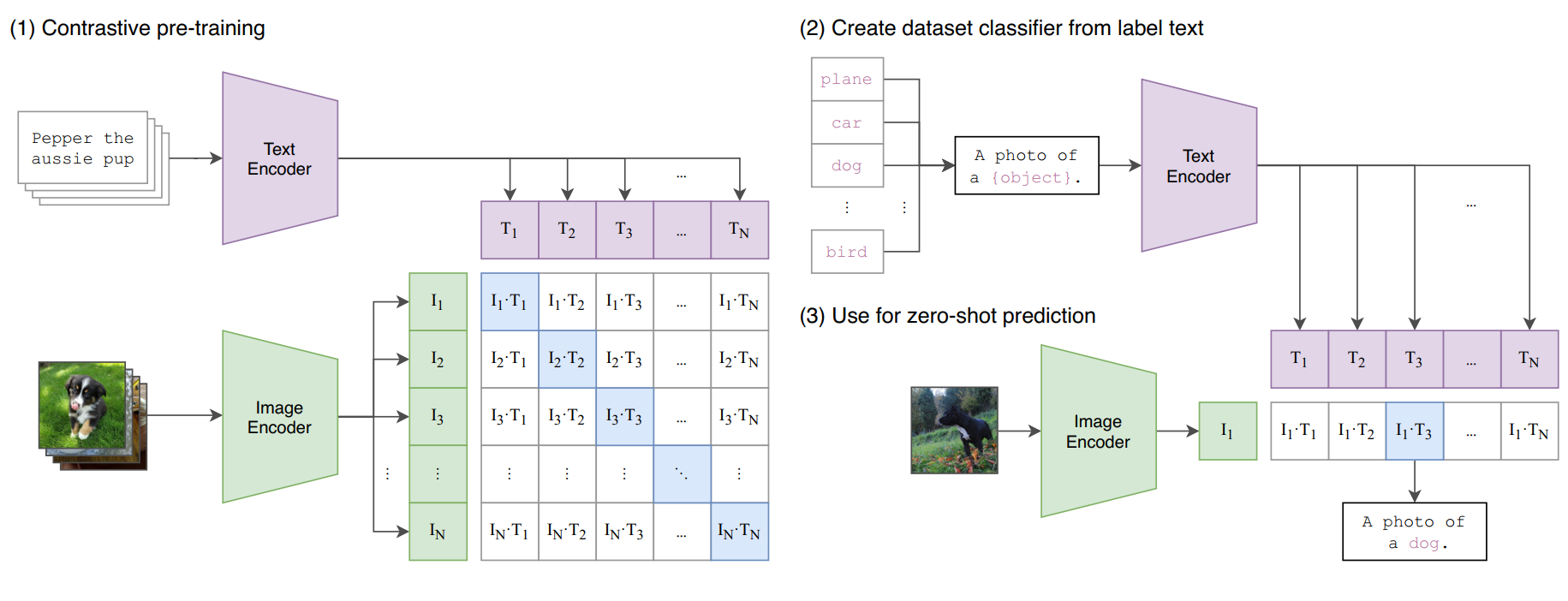
Generate text and image embeddings for semantic search and cross-modal retrieval. Accepts text or an image and returns a...

Generate CLIP ViT-L/14 embeddings from text and images for cross-modal similarity search and retrieval. Accept text stri...

Create 512-dimensional embeddings for images and text for similarity search, semantic retrieval, and clustering. Accept...

Converts text and images into vector embeddings for similarity search and multimodal analysis. Supports 89 languages for...

Generate instruction-tuned text embeddings for documents and queries, with an optional relevance score for query–documen...

Generate multilingual text embeddings and a relevance score from a query and a passage. Takes a text query and a text pa...