🤖 Model 🖼️

openai/clip
Convert text or images into 768-dimensional vector embeddings that capture semantic meaning. Uses OpenAI's CLIP model to...
Found 14 models (showing 1-14)
Convert text or images into 768-dimensional vector embeddings that capture semantic meaning. Uses OpenAI's CLIP model to...
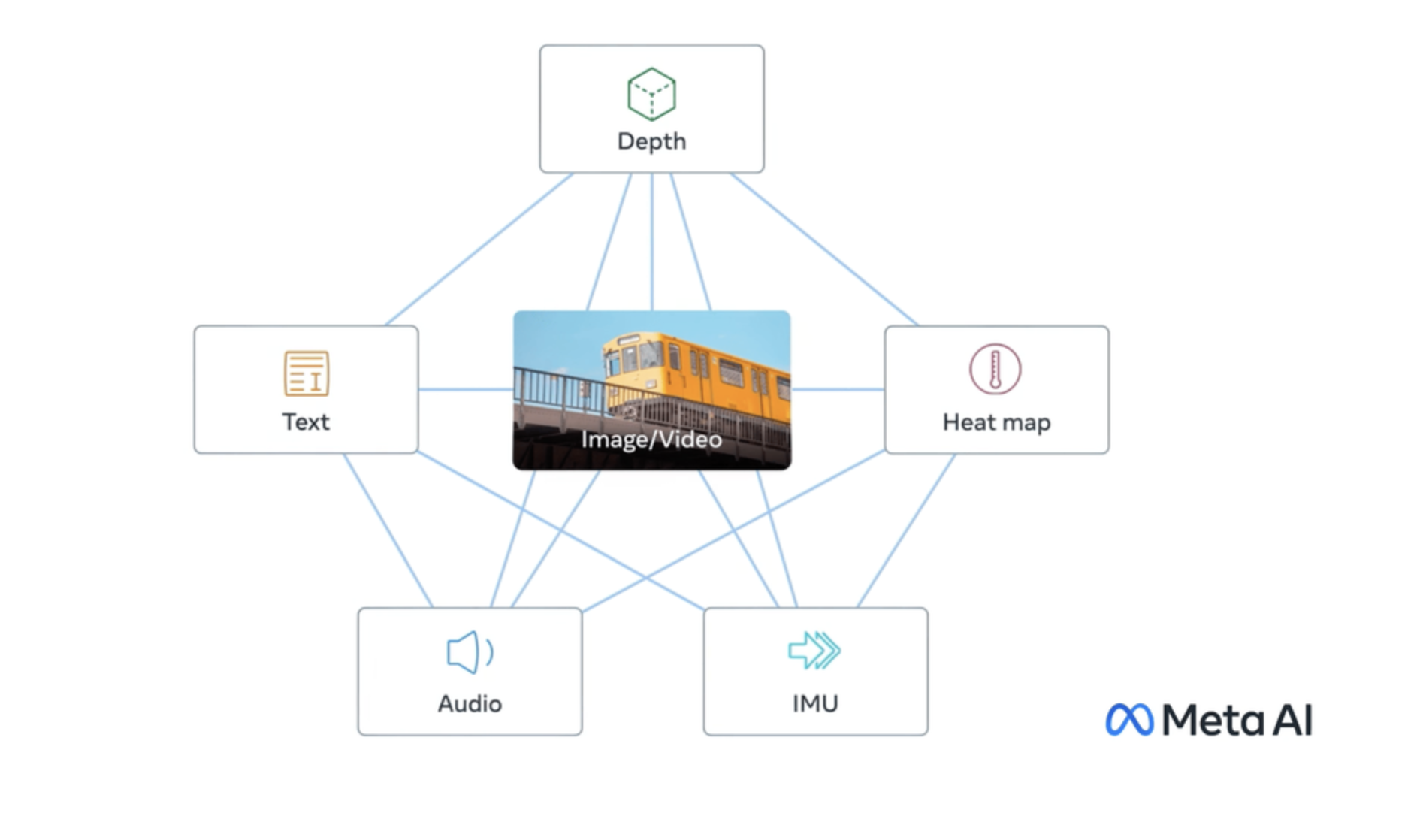
Generate shared embeddings for text, images, and audio for cross-modal retrieval and similarity search. Accepts a text s...
Generate dense embeddings for text queries and document screenshots to power document, PDF, webpage, and slide retrieval...
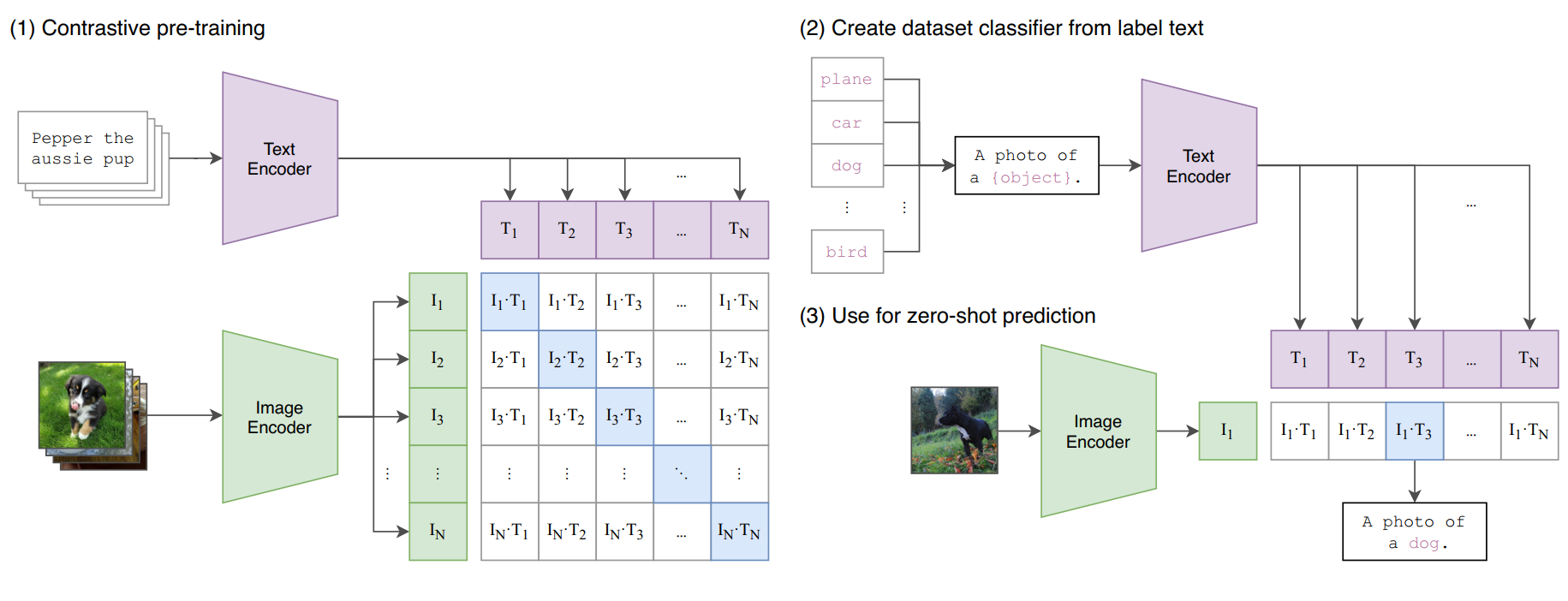
Generate text and image embeddings for semantic search and cross-modal retrieval. Accepts text or an image and returns a...

Generate CLIP ViT-L/14 embeddings from text and images for cross-modal similarity search and retrieval. Accept text stri...

Create 512-dimensional embeddings for images and text for similarity search, semantic retrieval, and clustering. Accept...

Converts text and images into vector embeddings for similarity search and multimodal analysis. Supports 89 languages for...
Embed images and text into a shared CLIP vector space for similarity search, cross-modal retrieval, and zero-shot classi...

Generate image embeddings from an input image for use with the Segment Anything Model (SAM) ViT-H. Accepts a single imag...

Compute CLIP embeddings for batches of text and images. Accept multiple newline-separated inputs and return one vector e...

Convert images into vector embeddings for visual similarity search, image retrieval, near-duplicate detection, clusterin...

Convert images into 64-dimensional embeddings for visual similarity search, retrieval, clustering, and downstream ML tas...

Calculates similarity scores between an input image and multiple text descriptions using OpenAI's CLIP (Contrastive Lang...

Classify images using candidate text labels through a multimodal vision-language model. Takes an image and comma-separat...