ignaciosgithub/pllava 🖼️🔢📝 → 📝
Performance
2.7sTypical run time
300Total runs
About
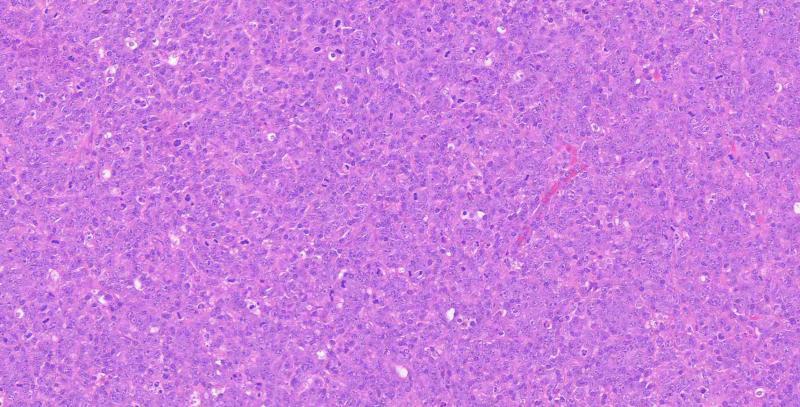
Example Output
Prompt:
"que se puede decir de esta imagen histopatologica?"
Output
Consistente con Linfoma difuso de grandes células.
Se realizaran técnicas de inmunohistqouímica para categorización.
Se realizaran técnicas de inmunohistqouímica para categorización.
Performance Metrics
2.71s
Prediction Time
2.75s
Total Time
All Input Parameters
{
"image": "https://replicate.delivery/pbxt/KSjaaQ4oatw4iARoNoU7orjhXpwB9m2LlOd4ifpe1gqZXWIo/img3.12.jpg",
"top_p": 1,
"prompt": "que se puede decir de esta imagen histopatologica?",
"max_tokens": 1024,
"temperature": 0.2
}
Input Parameters
- image (required)
- Input image
- top_p
- When decoding text, samples from the top p percentage of most likely tokens; lower to ignore less likely tokens
- prompt (required)
- Prompt to use for text generation
- max_tokens
- Maximum number of tokens to generate. A word is generally 2-3 tokens
- temperature
- Adjusts randomness of outputs, greater than 1 is random and 0 is deterministic
Output Schema
Output
Version Details
- Version ID
236f09a694cc81ea40e191c9102e7c698e2416d3083c872ae917b136ceb807f6- Version Created
- February 25, 2024