justmalhar/flux-mobile-ui 🖼️🔢❓📝✓ → 🖼️
Performance
16.5sTypical run time
798Total runs
About
Generate detailed mobile app user interfaces (UIs) using prefix “MOBIUI containing..” in 4-15 steps.
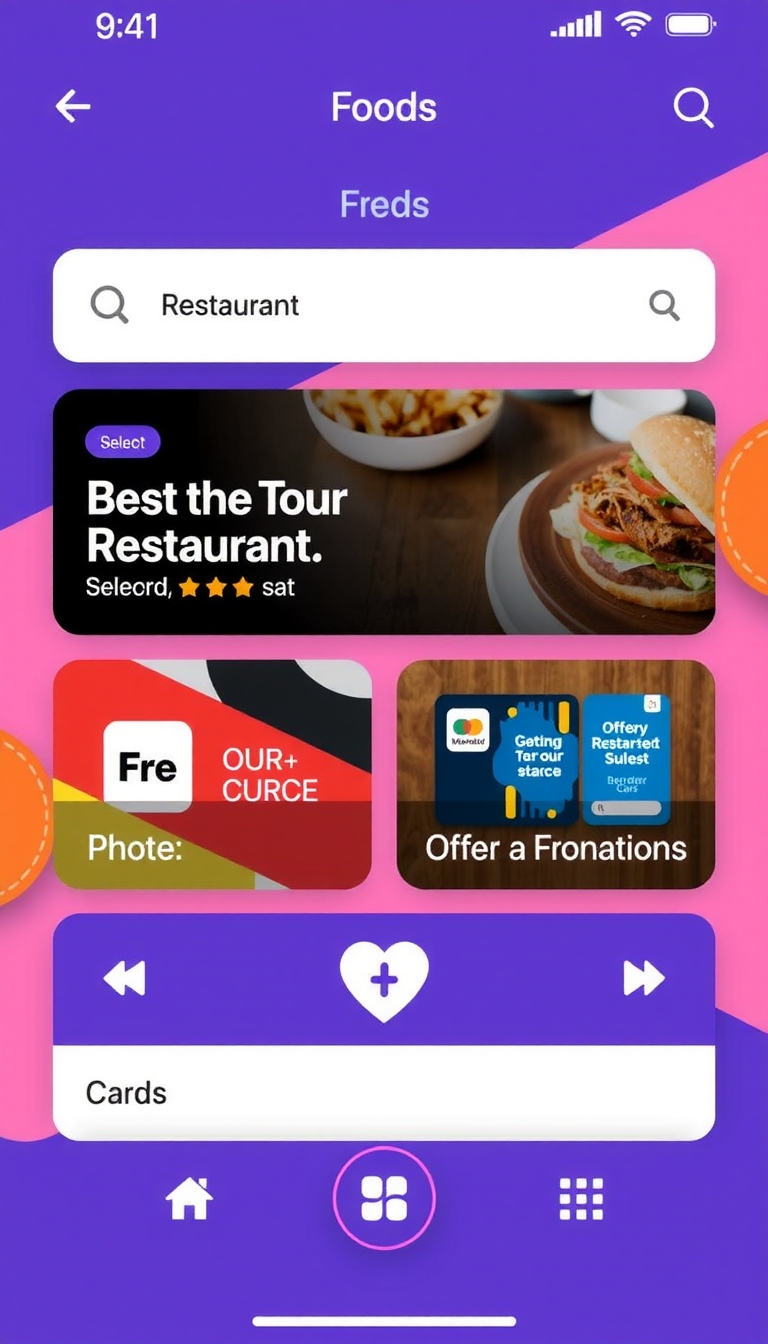
Example Output
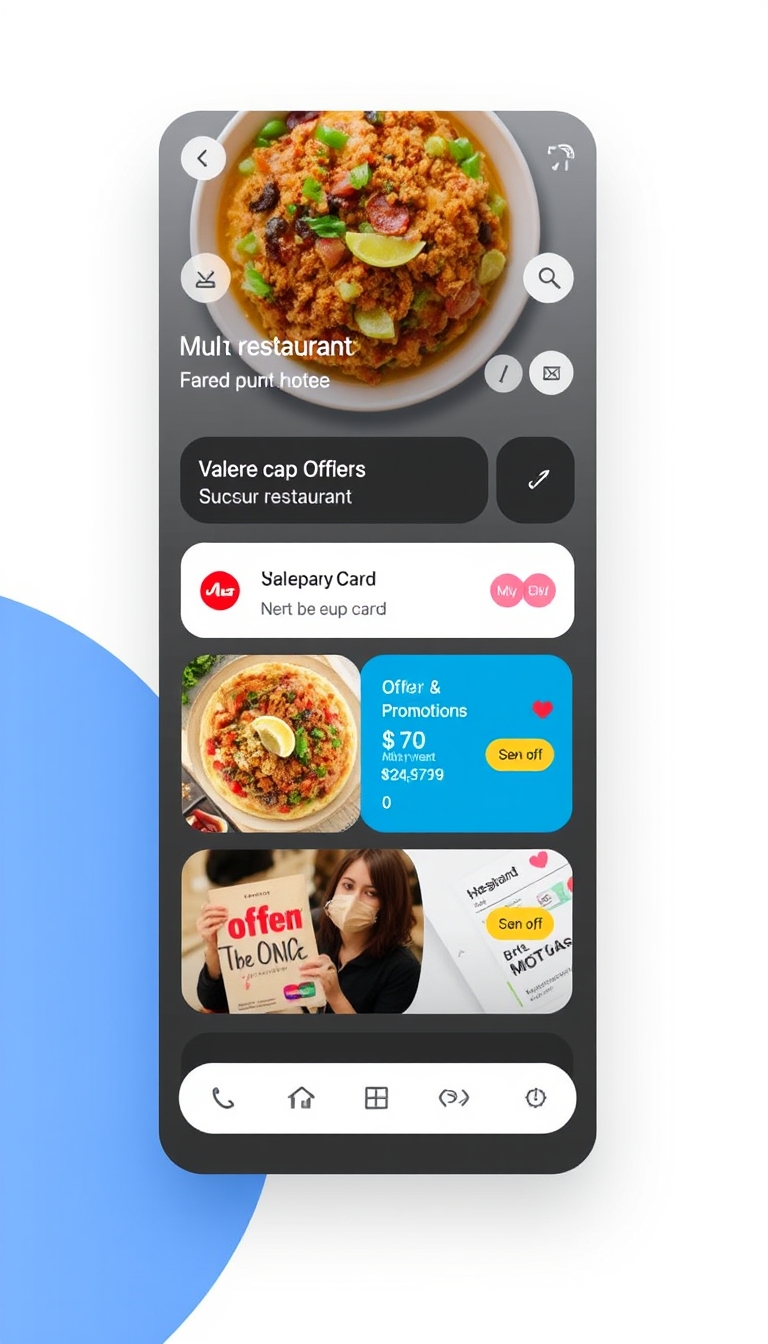
Prompt:
"MOBIUI containing a food ordering app screen, multiple restaurant selection options, bottom navigation bar, cards, offers and promotions card, app ui, mobile user interface "
Output
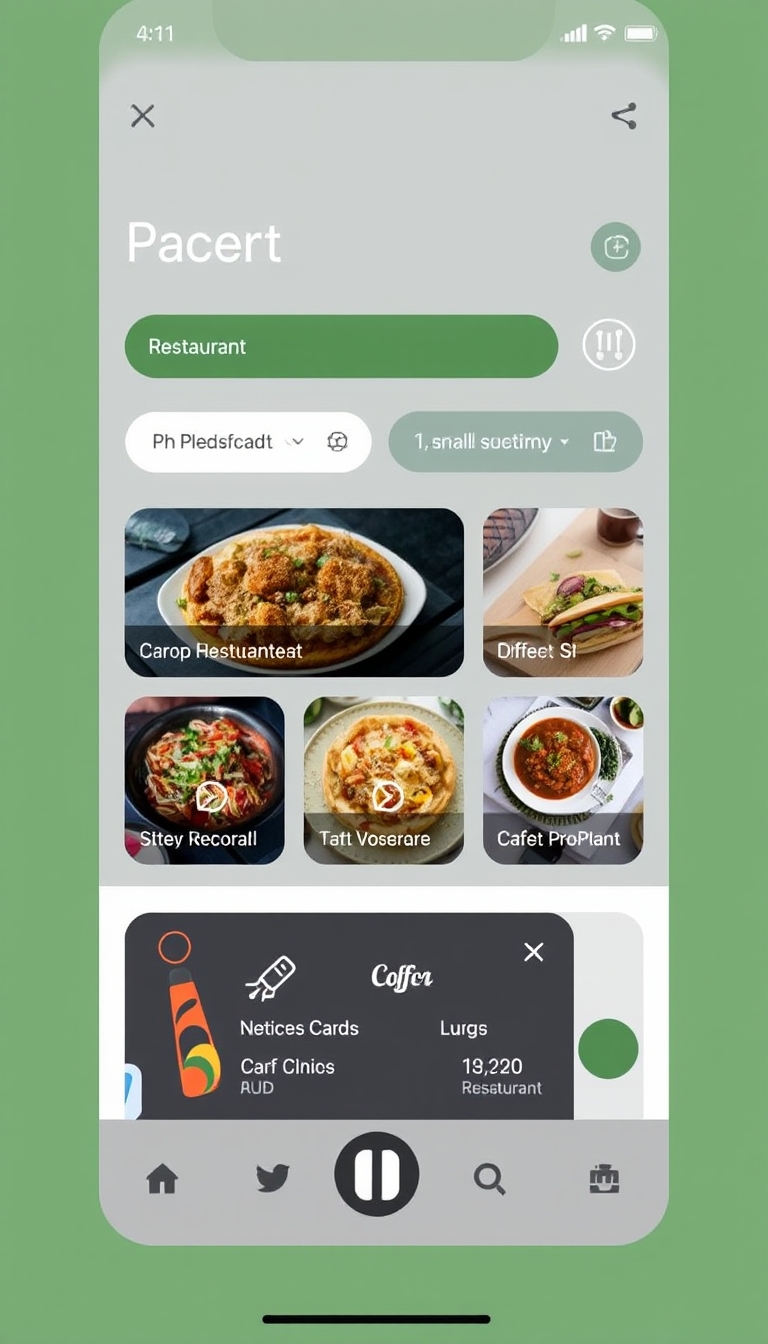
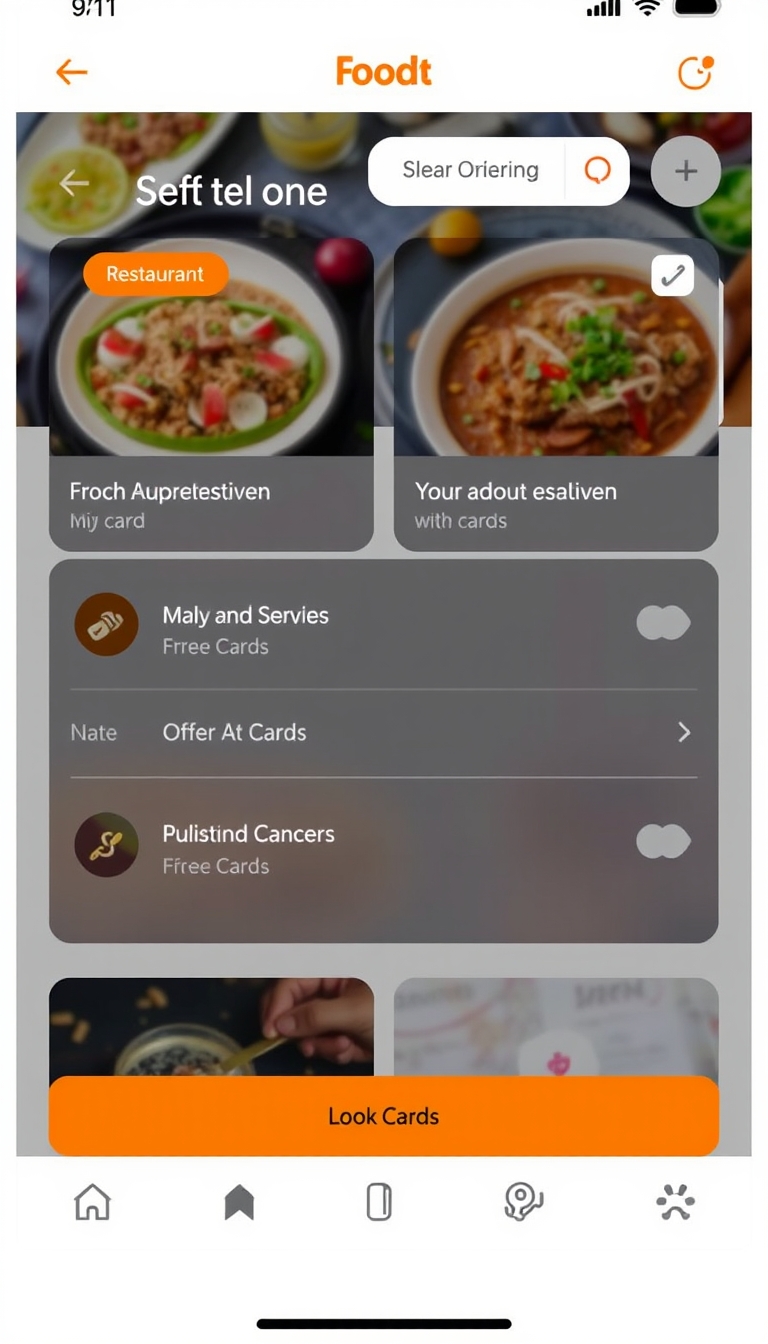
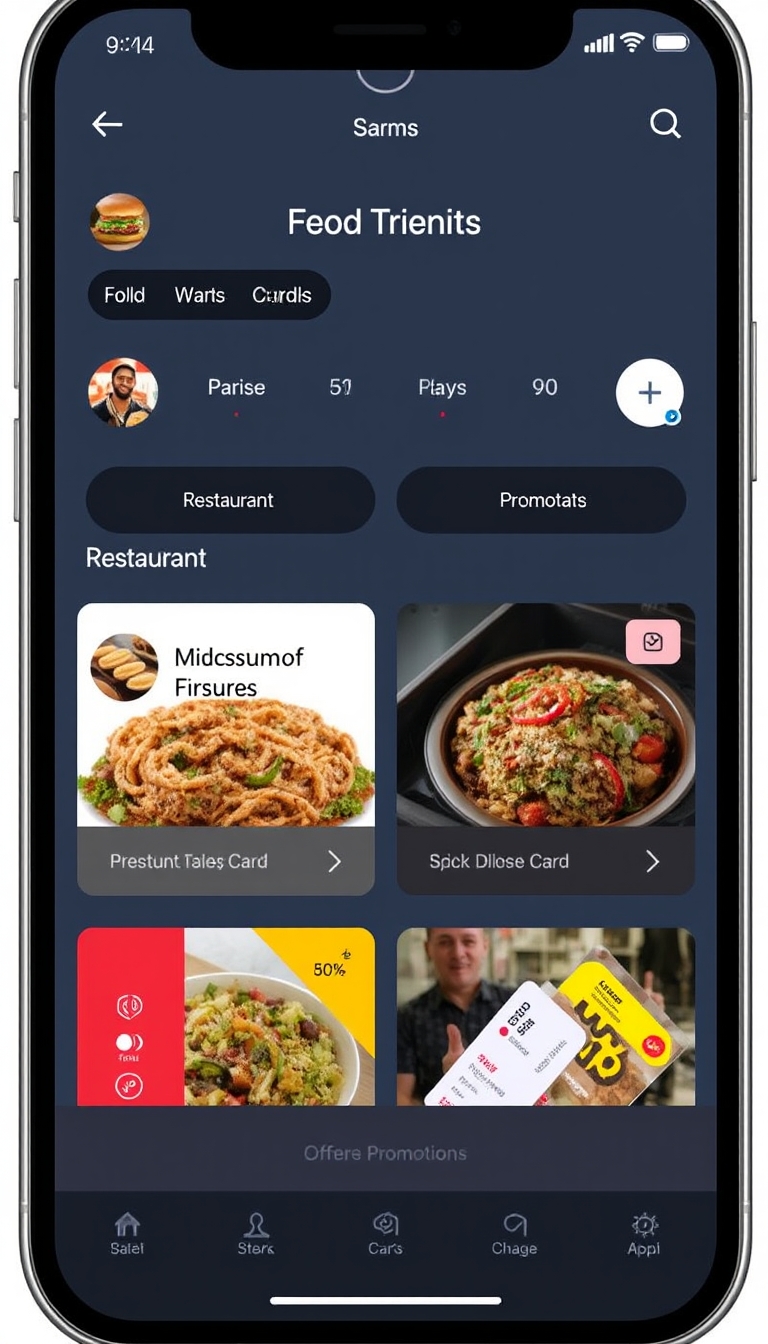
Performance Metrics
16.46s
Prediction Time
16.47s
Total Time
All Input Parameters
{
"model": "schnell",
"prompt": "MOBIUI containing a food ordering app screen, multiple restaurant selection options, bottom navigation bar, cards, offers and promotions card, app ui, mobile user interface ",
"lora_scale": 1,
"num_outputs": 4,
"aspect_ratio": "9:16",
"output_format": "jpg",
"guidance_scale": 3.5,
"output_quality": 100,
"num_inference_steps": 4
}
Input Parameters
- mask
- Image mask for image inpainting mode. If provided, aspect_ratio, width, and height inputs are ignored.
- seed
- Random seed. Set for reproducible generation
- image
- Input image for image to image or inpainting mode. If provided, aspect_ratio, width, and height inputs are ignored.
- model
- Which model to run inference with. The dev model performs best with around 28 inference steps but the schnell model only needs 4 steps.
- width
- Width of generated image. Only works if `aspect_ratio` is set to custom. Will be rounded to nearest multiple of 16. Incompatible with fast generation
- height
- Height of generated image. Only works if `aspect_ratio` is set to custom. Will be rounded to nearest multiple of 16. Incompatible with fast generation
- prompt (required)
- Prompt for generated image. If you include the `trigger_word` used in the training process you are more likely to activate the trained object, style, or concept in the resulting image.
- go_fast
- Run faster predictions with model optimized for speed (currently fp8 quantized); disable to run in original bf16
- extra_lora
- Load LoRA weights. Supports Replicate models in the format <owner>/<username> or <owner>/<username>/<version>, HuggingFace URLs in the format huggingface.co/<owner>/<model-name>, CivitAI URLs in the format civitai.com/models/<id>[/<model-name>], or arbitrary .safetensors URLs from the Internet. For example, 'fofr/flux-pixar-cars'
- lora_scale
- Determines how strongly the main LoRA should be applied. Sane results between 0 and 1 for base inference. For go_fast we apply a 1.5x multiplier to this value; we've generally seen good performance when scaling the base value by that amount. You may still need to experiment to find the best value for your particular lora.
- megapixels
- Approximate number of megapixels for generated image
- num_outputs
- Number of outputs to generate
- aspect_ratio
- Aspect ratio for the generated image. If custom is selected, uses height and width below & will run in bf16 mode
- output_format
- Format of the output images
- guidance_scale
- Guidance scale for the diffusion process. Lower values can give more realistic images. Good values to try are 2, 2.5, 3 and 3.5
- output_quality
- Quality when saving the output images, from 0 to 100. 100 is best quality, 0 is lowest quality. Not relevant for .png outputs
- prompt_strength
- Prompt strength when using img2img. 1.0 corresponds to full destruction of information in image
- extra_lora_scale
- Determines how strongly the extra LoRA should be applied. Sane results between 0 and 1 for base inference. For go_fast we apply a 1.5x multiplier to this value; we've generally seen good performance when scaling the base value by that amount. You may still need to experiment to find the best value for your particular lora.
- replicate_weights
- Load LoRA weights. Supports Replicate models in the format <owner>/<username> or <owner>/<username>/<version>, HuggingFace URLs in the format huggingface.co/<owner>/<model-name>, CivitAI URLs in the format civitai.com/models/<id>[/<model-name>], or arbitrary .safetensors URLs from the Internet. For example, 'fofr/flux-pixar-cars'
- num_inference_steps
- Number of denoising steps. More steps can give more detailed images, but take longer.
- disable_safety_checker
- Disable safety checker for generated images.
Output Schema
Output
Example Execution Logs
Using seed: 36769 Prompt: MOBIUI containing a food ordering app screen, multiple restaurant selection options, bottom navigation bar, cards, offers and promotions card, app ui, mobile user interface txt2img mode Using schnell model Loading LoRA weights Ensuring enough disk space... Free disk space: 9322812465152 Downloading weights 2024-08-23T10:24:27Z | INFO | [ Initiating ] chunk_size=150M dest=/src/weights-cache/2c8f74d277701d7c url=https://replicate.delivery/yhqm/v6e5FP2DnMTdf0VlCxKJBG0WC5yJB5UC1n2LwkzSlEsw1gVTA/trained_model.tar 2024-08-23T10:24:29Z | INFO | [ Complete ] dest=/src/weights-cache/2c8f74d277701d7c size="181 MB" total_elapsed=1.618s url=https://replicate.delivery/yhqm/v6e5FP2DnMTdf0VlCxKJBG0WC5yJB5UC1n2LwkzSlEsw1gVTA/trained_model.tar b'' Downloaded weights in 1.6485824584960938 seconds LoRA weights loaded successfully 0%| | 0/4 [00:00<?, ?it/s] 25%|██▌ | 1/4 [00:00<00:02, 1.03it/s] 50%|█████ | 2/4 [00:01<00:01, 1.20it/s] 75%|███████▌ | 3/4 [00:02<00:00, 1.13it/s] 100%|██████████| 4/4 [00:03<00:00, 1.10it/s] 100%|██████████| 4/4 [00:03<00:00, 1.11it/s]
Version Details
- Version ID
1bf3362039a0ba88a625bff817a559bd8466428ae5a357e172fabfd4fe066fdf- Version Created
- August 23, 2024