lucataco/smolvlm-instruct 🖼️📝🔢 → 📝
Performance
0.5sTypical run time
8.3KTotal runs
About
SmolVLM-Instruct by HuggingFaceTB
Example Output
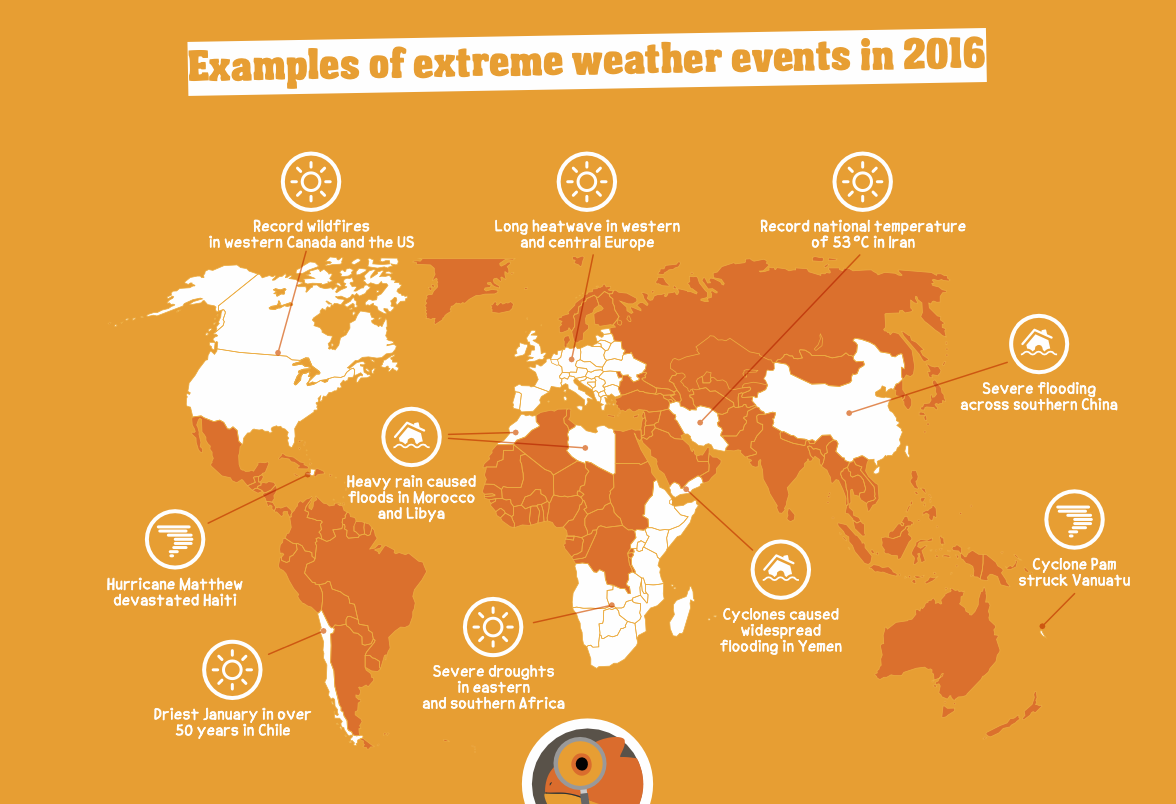
Prompt:
"Where do the severe droughts happen according to this image?"
Output
The severe droughts happen in eastern and southern Africa.
Performance Metrics
0.50s
Prediction Time
0.51s
Total Time
All Input Parameters
{
"image": "https://replicate.delivery/pbxt/M41uQ4M8J9FEqxRJ0tNnliJF2PNJIeGjdid66k2uHOLgv5OJ/weather.png",
"prompt": "Where do the severe droughts happen according to this image?",
"max_new_tokens": 500
}
Input Parameters
- image (required)
- Input image to process
- prompt
- Text prompt to guide the model's response
- max_new_tokens
- Maximum number of tokens to generate
Output Schema
Output
Version Details
- Version ID
e79f1e0eb64fe9a145d0a0afd6127d43b37de66eaaa2e00ff3d165bc14097dfb- Version Created
- November 30, 2024