🤖 Model 🔊

zsxkib/audio-flamingo-3
Analyze audio and answer questions about speech, music, and sound effects. Accepts an audio file and an optional text pr...
Found 11 models (showing 1-11)
Analyze audio and answer questions about speech, music, and sound effects. Accepts an audio file and an optional text pr...
Extract lip-sync mouth cues from speech audio and return time-aligned JSON for animation. Accepts common audio formats (...

Segment speakers in an audio file and return time-stamped speaker labels (diarization). Accepts audio plus optional num_...

Converts audio into text transcriptions with timestamps and provides AI-powered analysis of the content. Achieves 5.63%...
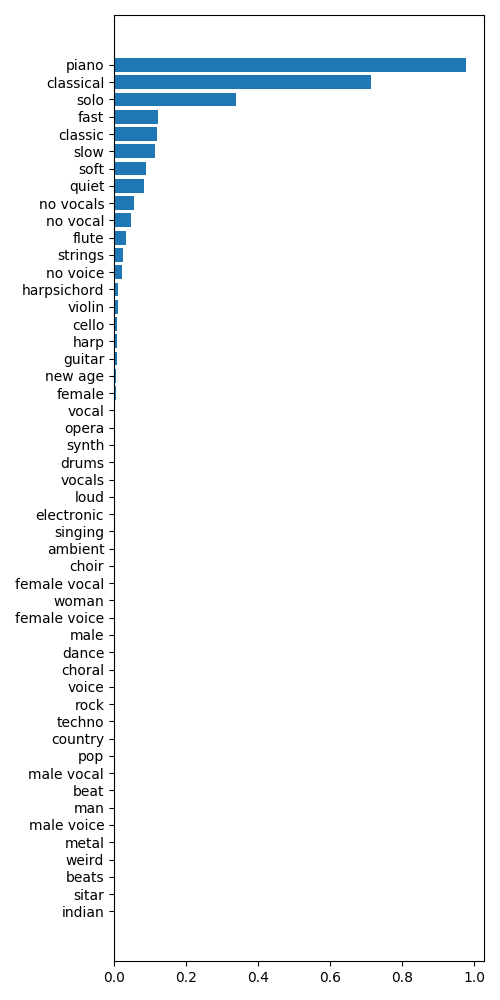
Generate music tags from audio files using state-of-the-art CNN-based models. Supports multiple model variants including...
Separate audio mixtures into individual tracks including bass, drums, vocals, and other components.
Transcribe and analyze audio content with Canary-Qwen-2.5B, a speech-to-text model that provides perfect transcription w...
Identify who spoke when in an audio file. Takes a single audio recording as input and returns a diarization JSON with sp...

Transcribe speech and analyze audio content with Q&A and summarization across multiple languages. Accepts an audio file...
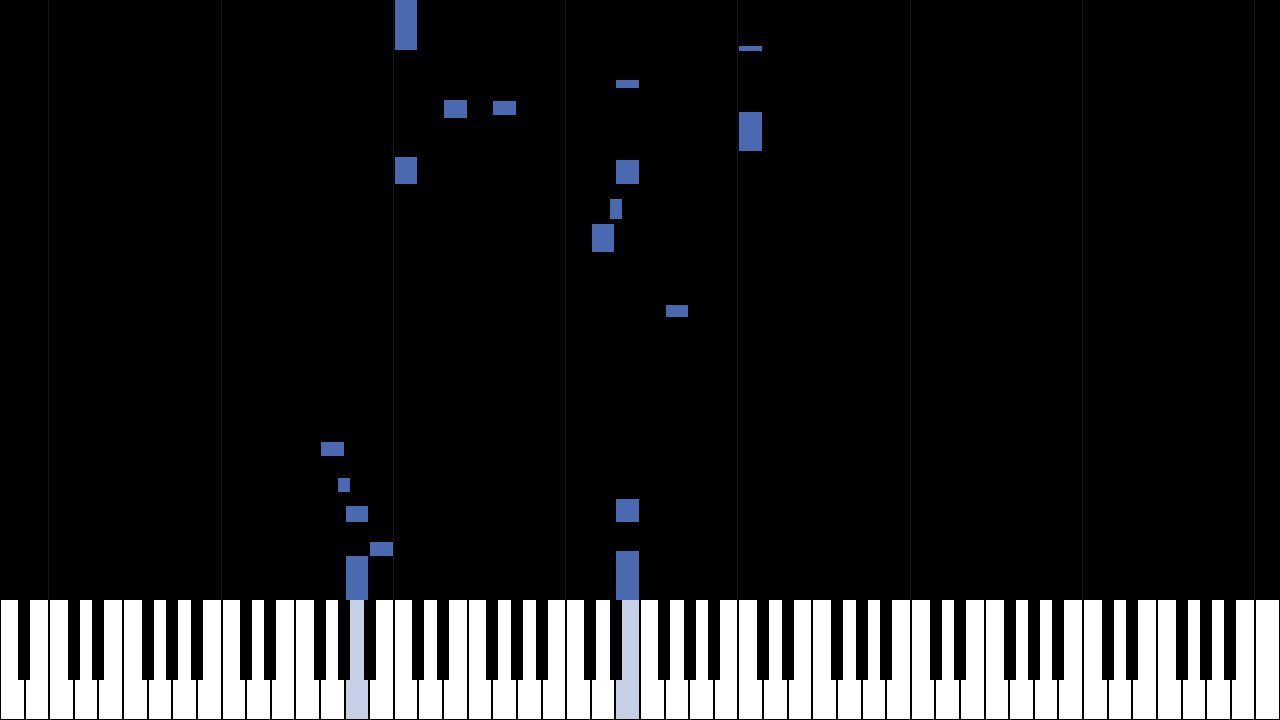
Transcribe piano audio into MIDI format and generate a Synthesia-style video visualization from the transcription. Utili...
Recognize and predict human emotions from speech audio files. Utilizes machine learning and deep learning algorithms to...