🤖 Model 🔊
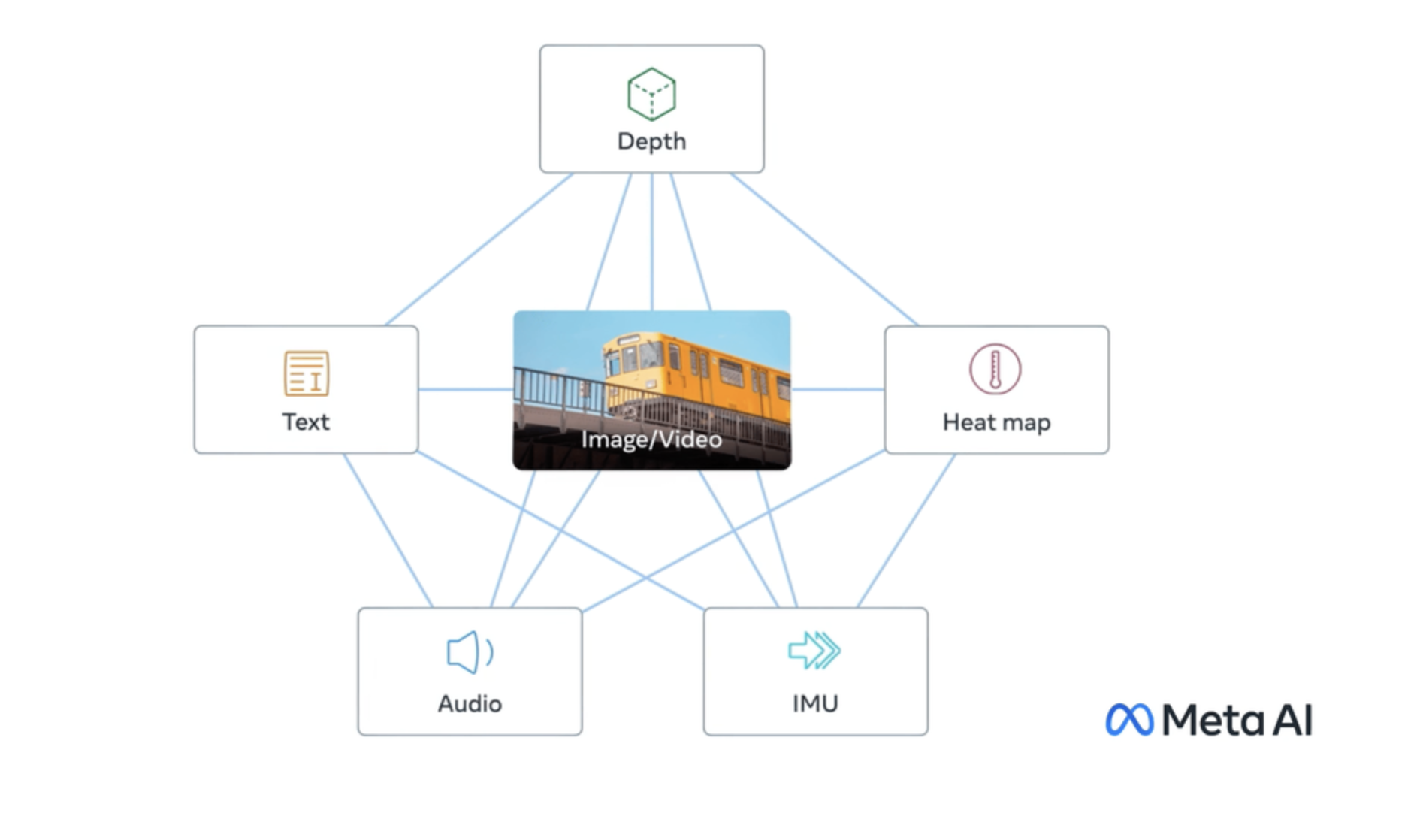
daanelson/imagebind
Generate shared embeddings for text, images, and audio for cross-modal retrieval and similarity search. Accepts a text s...
Audio embedding models convert audio signals into dense vector representations. These embeddings capture acoustic features like timbre, rhythm, genre, mood, and content — enabling similarity search, classification, clustering, and retrieval without manual labeling.
When comparing models, check the embedding dimension, whether they handle music vs. speech vs. general audio, and whether they support batch processing.
Found 6 models (showing 1-6)
Generate shared embeddings for text, images, and audio for cross-modal retrieval and similarity search. Accepts a text s...

Analyze music structure from an audio file. Return tempo (BPM), beats, downbeats, segment boundaries, and functional seg...

Analyze music to extract song structure, tempo (BPM), and downbeats, and optionally separate stems. Takes an audio file...
Segment speakers in audio recordings. Take an audio file and return time-stamped speech segments labeled by speaker, the...
Identify and segment speakers in an audio recording. Accepts an audio file and outputs JSON with time-stamped segments (...
Transcribe English speech from an audio input and label speakers with diarization. Return structured JSON with timestamp...
For production use, test embedding quality on your specific audio domain. A model trained on music may not produce meaningful embeddings for speech or environmental sounds. Also consider embedding dimension — higher dimensions capture more detail but increase storage and search costs.