🤖 Model 🖼️ → 📝

chenxwh/deepseek-vl2
Analyze images and answer questions about visual content using a Mixture-of-Experts vision-language model. Processes sin...
Found 69 models (showing 41-60)
Analyze images and answer questions about visual content using a Mixture-of-Experts vision-language model. Processes sin...

Analyze images and videos with text prompts to generate detailed text responses. Handles single images, multiple images,...

Performs multiple vision and vision-language tasks based on text prompts. Supports image captioning with varying detail...

Generates text responses based on image and text inputs using Meta's Llama 3.2-Vision 90B multimodal language model. Per...

Analyze images to generate captions, detect objects, and extract text (OCR). Accepts an image plus a task selector and o...

Analyze images and answer questions about visual content using a Mixture-of-Experts vision-language model. Takes an imag...

Generates text responses based on both text prompts and images using Meta's Llama 3.2 Vision 11B model. Analyzes and und...
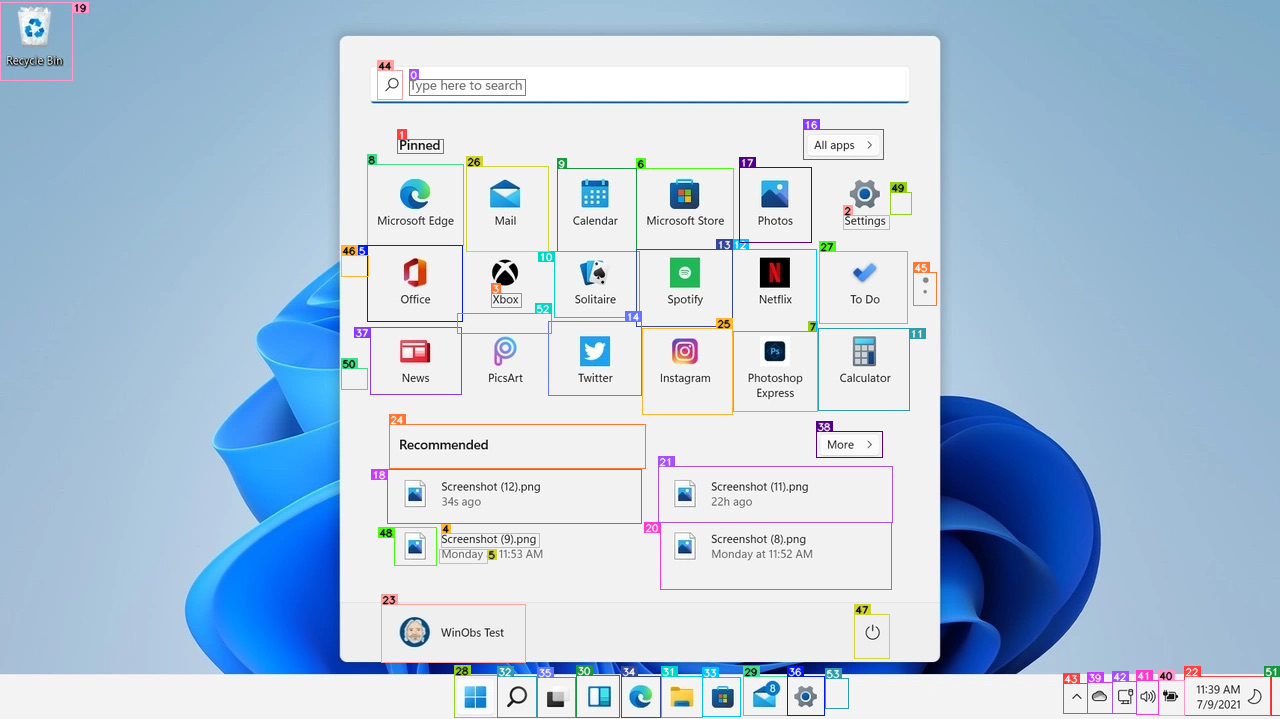
Parse GUI screenshots into structured UI elements with bounding boxes and captions. Accepts an image of a desktop or mob...
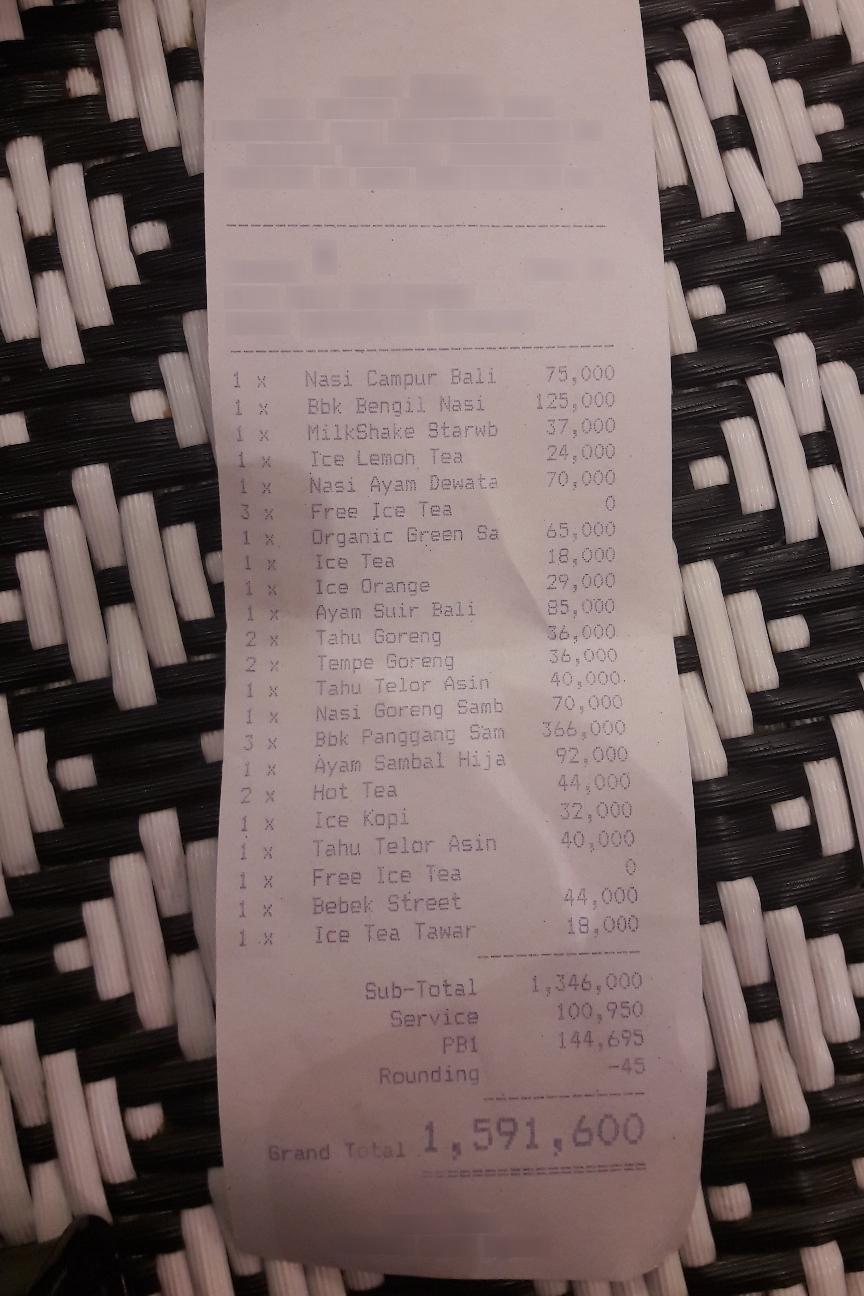
Extract structured purchase data from receipt images as JSON. Input a receipt image and output JSON with line items, qua...
Extract text from images and documents in 90+ languages with OCR, returning plain text plus optional structured layout....
Convert documents to Markdown and structured JSON. Accept PDF, DOC/DOCX, PPT/PPTX, and image files (PNG/JPG/WEBP) as inp...

Converts images containing documents, PDFs, charts, and handwritten text into structured markdown while preserving forma...

Analyzes images and answers questions about them through conversational interaction. Takes an image and a text prompt as...

Analyzes images and videos to answer questions, extract data, and provide detailed descriptions. Supports processing up...
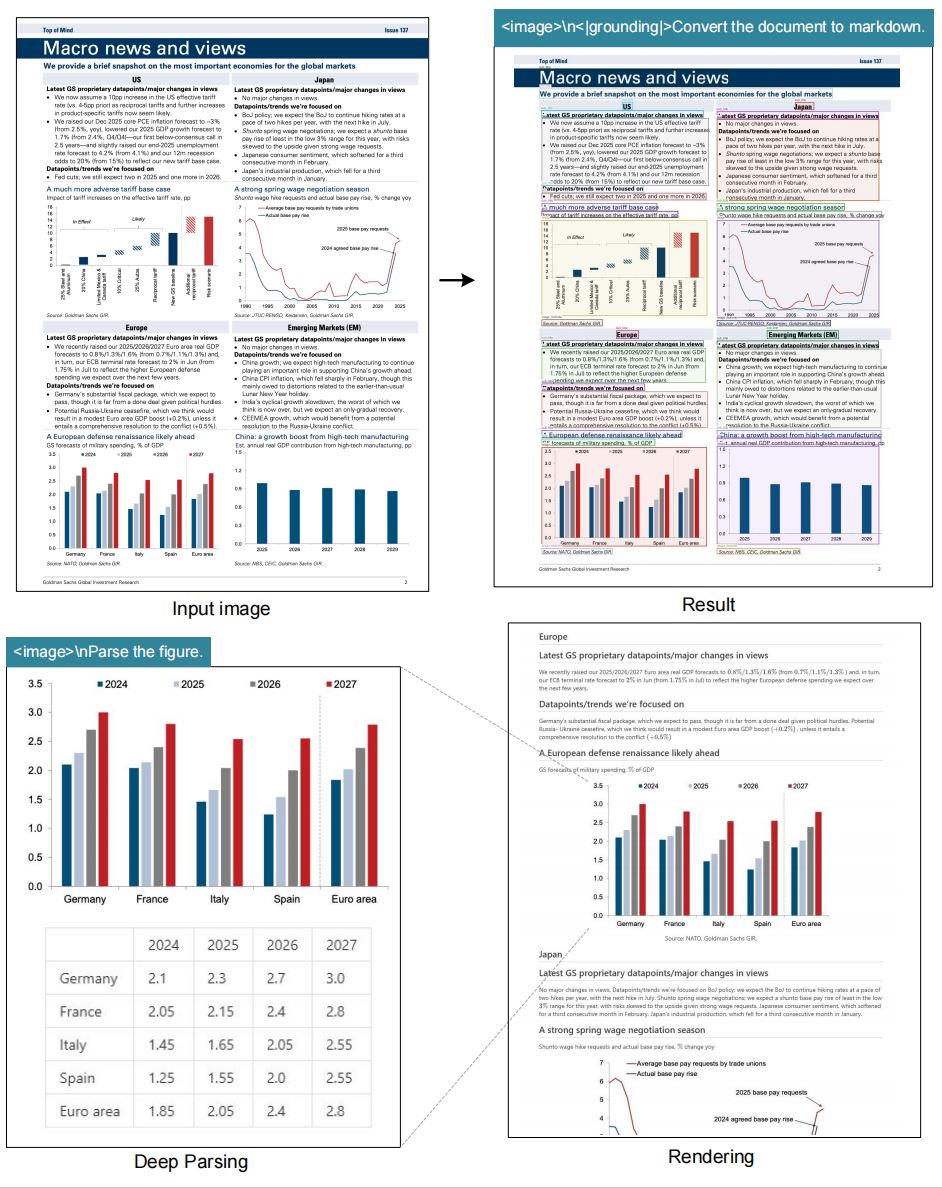
Extract text and convert documents to markdown format from images using optical character recognition. Supports multiple...

Extract text and tables from document images or PDFs. Accepts an image or a selected PDF page and returns structured tex...

Answer questions about images and generate captions from an image input and a natural-language question, returning text....

Analyzes images and answers questions about visual content with spatially-aware responses. Takes an image and a text pro...

Analyzes images and generates text responses based on both the image content and text prompts. Uses a locality-enhanced...

Caption images and answer visual questions from an image plus an optional text prompt, returning text. Handle OCR-style...