🤖 Model 🔊

zsxkib/audio-flamingo-3
Analyze audio and answer questions about speech, music, and sound effects. Accepts an audio file and an optional text pr...
Found 77 models (showing 1-20)
Analyze audio and answer questions about speech, music, and sound effects. Accepts an audio file and an optional text pr...

Transcribe speech and generate spoken replies from an audio input. Accepts an audio file (with an optional text prompt)...

Transcribe, translate, summarize, and answer questions from audio input, returning text. Supports dedicated transcriptio...

Answer spoken queries with simultaneous text and speech output. Accepts a speech audio input and an optional instruction...

Converts audio into text transcriptions with timestamps and provides AI-powered analysis of the content. Achieves 5.63%...

Process text, images, audio, and video inputs to generate text and speech responses simultaneously. Features a novel Thi...
Transcribe speech to text from an audio file. Return structured transcripts with sentence/phrase segments plus per-word...

Transcribe or translate speech to text from audio input. Run Whisper Large v3 with batched inference and Flash Attention...
Converts audio files to text transcriptions using GPT-4o for improved accuracy over traditional Whisper models. Supports...

Transcribe speech from audio into text. Perform multilingual automatic speech recognition with language detection and op...

Transcribe audio with speaker diarization. Takes an audio input and returns a text transcript with per-speaker labels, s...
Transcribes audio to text using GPT-4o mini, offering improved word error rate and better language recognition compared...

Transcribe audio to text with word-level timestamps and optional speaker diarization. Accepts an audio file with optiona...

Transcribe English speech to text from an input audio file. Uses an RNNT FastConformer ASR model co-developed by NVIDIA...

Transcribe speech from online videos into timestamped text. Accepts a video URL (YouTube and other supported sites) and...

Transcribe and structure spoken conversations from an audio input. Accept an audio file with optional session context (u...

Translate speech and text across 100+ languages, returning text and optionally synthesized speech. Accept audio or text...

Transcribe audio to text with fast, batched speech recognition. Accept an audio file as input and return a transcript wi...
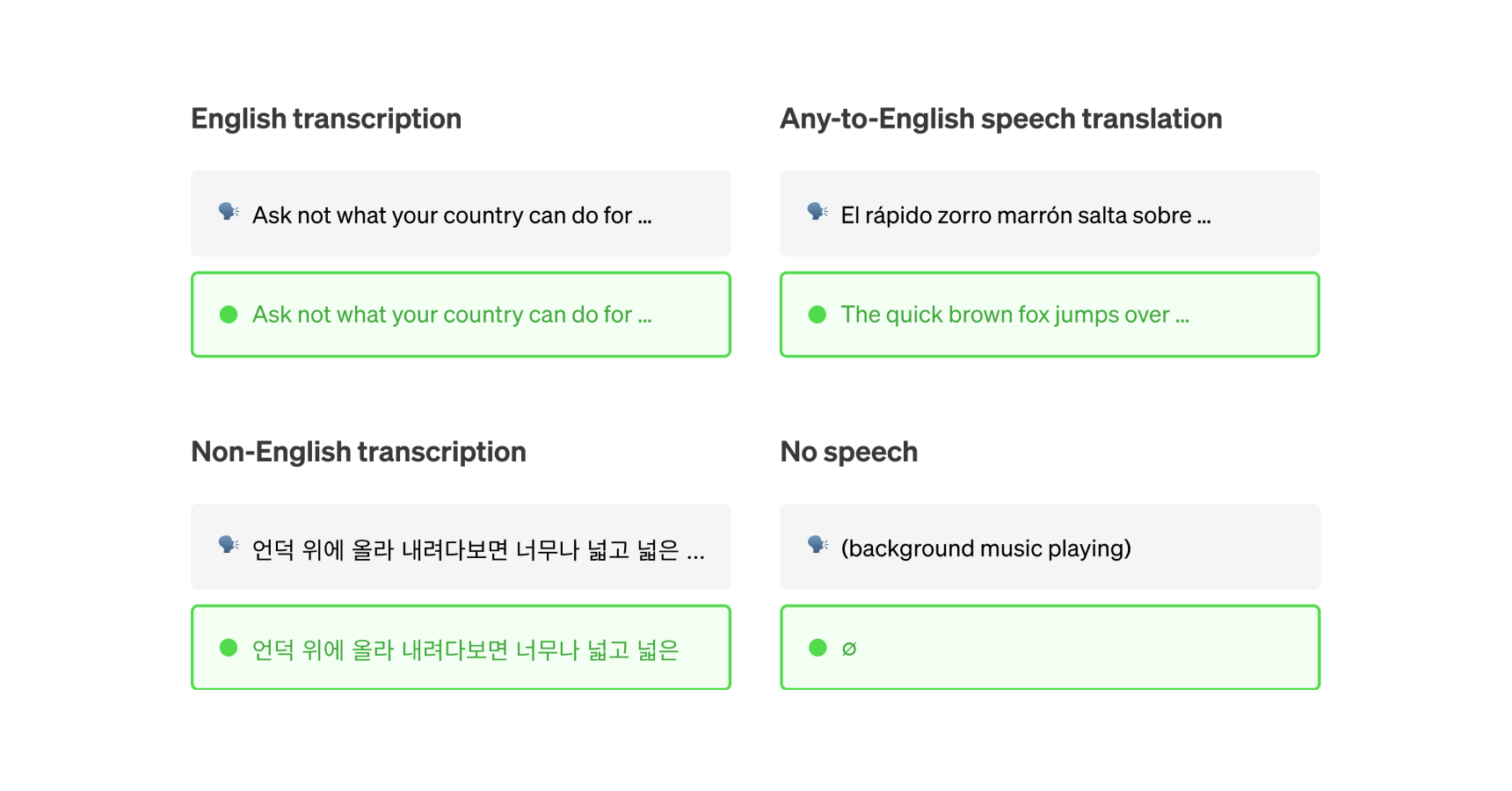
Generate subtitles from an audio file. Transcribe speech to text and return time-aligned subtitles (SRT or VTT), the ful...

Transcribe and translate speech to text from audio input. Supports multilingual ASR in English, French, German, Spanish,...