camenduru/minigpt4-video 📝🖼️✓ → 📝
Performance
14.4sTypical run time
~333sCold start (first call)
843Total runs
About
MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens
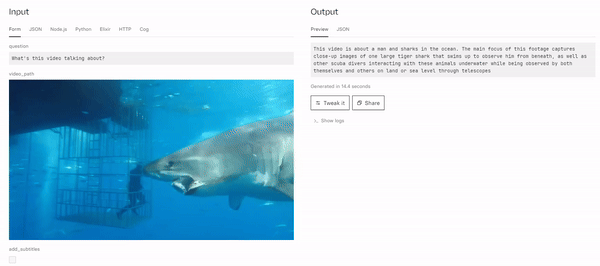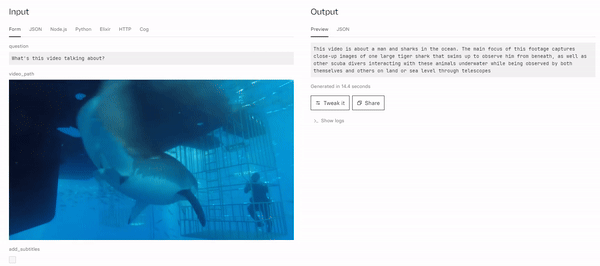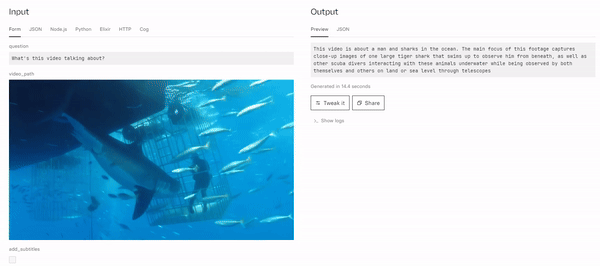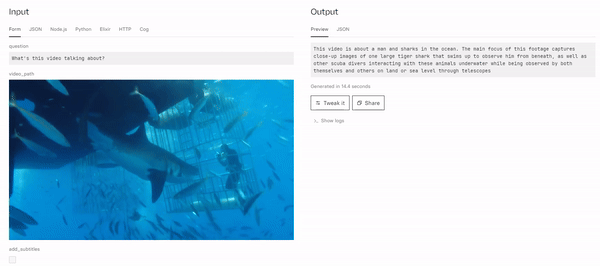
Example Output
Output
This video is about a man and sharks in the ocean. The main focus of this footage captures close-up images of one large tiger shark that swims up to observe him from beneath, as well as other scuba divers interacting with these animals underwater while being observed by both themselves and others on land or sea level through telescopes
Performance Metrics
14.43s
Prediction Time
333.08s
Total Time
All Input Parameters
{
"question": "What's this video talking about?",
"video_path": "https://replicate.delivery/pbxt/Ki1Xy9IzGUX16CXvlMU1f9VYq89OpJk7hihhBR0CjScxp6so/Great%20white%20shark%20swims%20into%20cage.mp4",
"add_subtitles": false
}
Input Parameters
- question
- video_path (required)
- Input video
- add_subtitles
Output Schema
Output
Example Execution Logs
WARNING:py.warnings:/usr/local/lib/python3.10/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants. warnings.warn( WARNING:py.warnings:/usr/local/lib/python3.10/site-packages/torch/utils/checkpoint.py:61: UserWarning: None of the inputs have requires_grad=True. Gradients will be None warnings.warn( img_embeds shape torch.Size([45, 64, 4096]) inputs_embeds shape torch.Size([1, 3034, 4096]) attention_mask shape torch.Size([1, 3034])
Version Details
- Version ID
5679342473d4fd99cf75e140a403e6463f8d5cdc324525783e0d7e35cf27f68b- Version Created
- April 8, 2024