🤖 Model 📝 → 📝
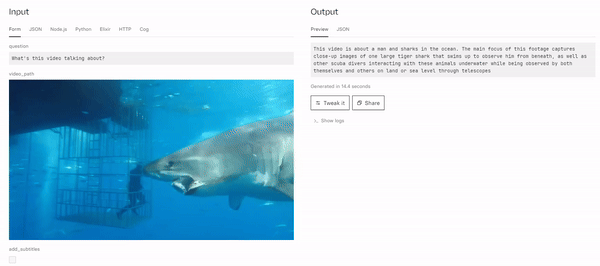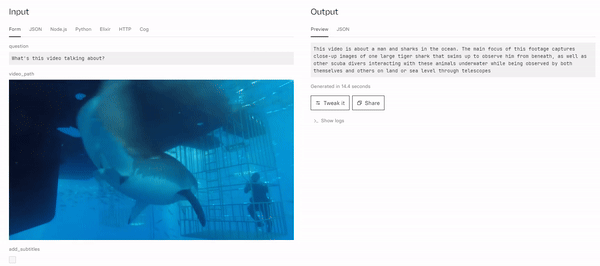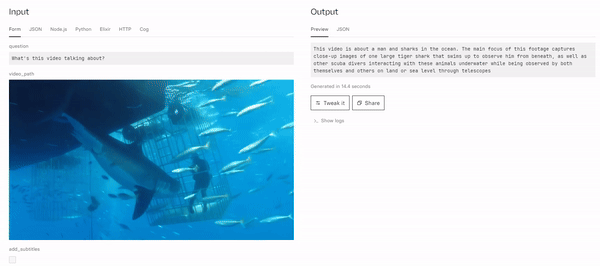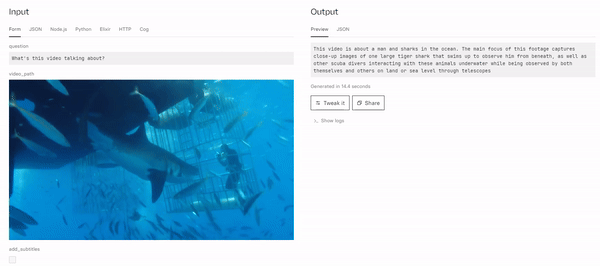
camenduru/minigpt4-video
Analyze and understand video content by generating textual descriptions from video inputs. This model uses interleaved v...
Found 9 models (showing 1-9)
Analyze and understand video content by generating textual descriptions from video inputs. This model uses interleaved v...
Generate realistic audio from video and text descriptions for professional-grade sound effect creation. Supports high-fi...
Moderate text prompts, model responses, and images for safety compliance. Accepts text with optional multiple images and...

Run any ComfyUI workflow to generate images or videos. Provide the workflow as ComfyUI API JSON (“Save (API format)”) wi...

Edit images based on textual instructions using a multimodal large language model. This model allows users to input an i...

Classify the safety of multimodal inputs (image and user message) for content moderation. Accepts an image (required) an...

Analyzes images and answers questions about them using a unified autoregressive framework for multimodal understanding....

Generate text responses from text, image, video, and audio inputs with controllable reasoning depth. Supports up to 1 mi...

Accepts arbitrary sequences of image and text inputs to produce text outputs for multimodal tasks. Answers questions abo...