declare-lab/tangoflux 🔢📝 → 🖼️
Performance
1.4sTypical run time
338.4KTotal runs
About
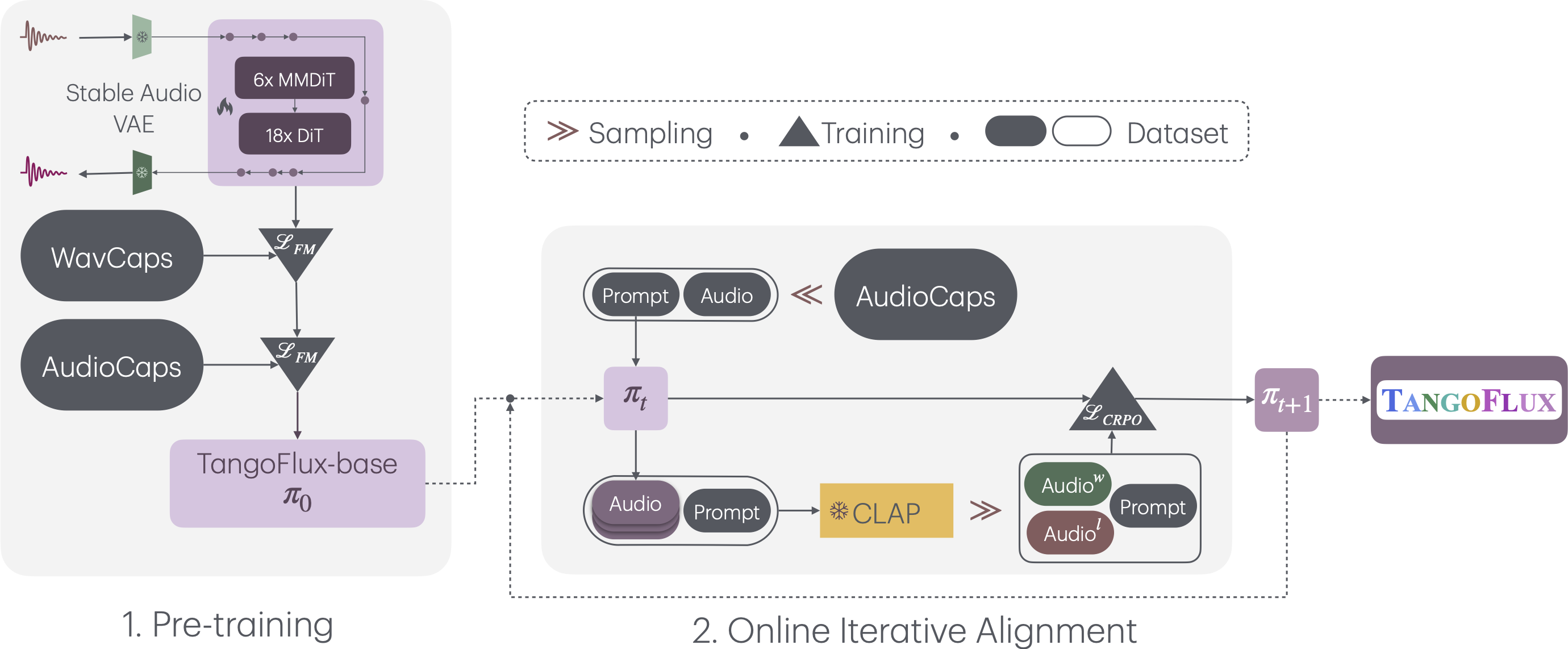
Super Fast and Faithful Text to Audio Generation with Flow Matching and Clap-Ranked Preference Optimization
Example Output
Prompt:
"The deep growl of an alligator ripples through the swamp as reeds sway with a soft rustle and a turtle splashes into the murky water"
Output
Performance Metrics
1.39s
Prediction Time
1.39s
Total Time
All Input Parameters
{
"steps": 25,
"prompt": "The deep growl of an alligator ripples through the swamp as reeds sway with a soft rustle and a turtle splashes into the murky water",
"duration": 10,
"guidance_scale": 4.5
}
Input Parameters
- steps
- Number of inference steps
- prompt
- Input prompt
- duration
- Duration of the output audio in seconds
- guidance_scale
- Scale for classifier-free guidance
Output Schema
Output
Example Execution Logs
0%| | 0/25 [00:00<?, ?it/s] 0%| | 0/25 [00:01<?, ?it/s]
Version Details
- Version ID
fcdc421786888a045329d7c4e1874764433a2516b21f4c34bd3da4e054d04cf9- Version Created
- December 31, 2024