🤖 Model 📝 → 🔊
smaerdlatigid/stable-audio
Generate audio clips from a text prompt. Input a descriptive prompt and a target duration to synthesize music, ambience,...
Found 17 models (showing 1-17)
Generate audio clips from a text prompt. Input a descriptive prompt and a target duration to synthesize music, ambience,...
Generate audio from a text prompt, including sound effects, ambience, and musical textures. Accepts a prompt (and option...
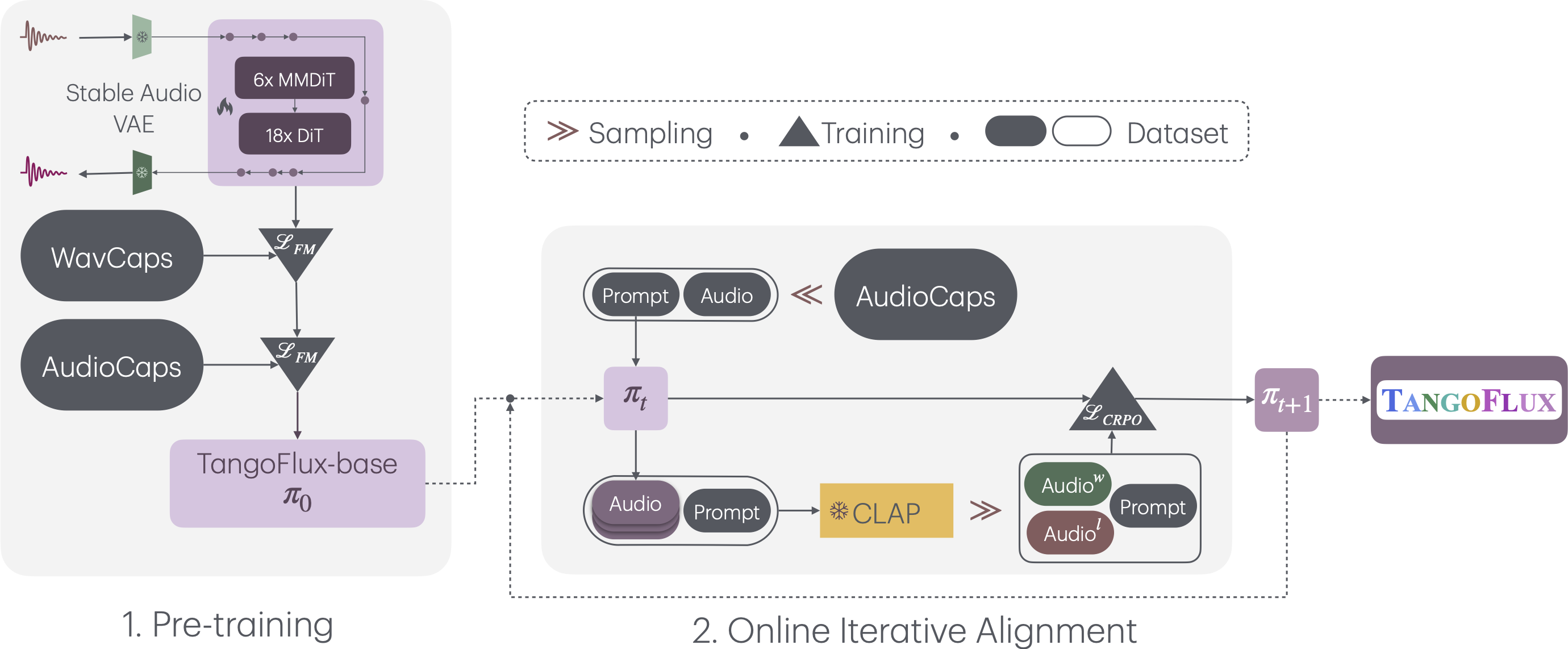
Generate audio from a text prompt. Produce 44.1 kHz sound effects and ambiences from natural language with user-set dura...

Generate sound effects and general non-music audio from a text prompt. Accepts a textual description and returns an audi...
Generate short genre-conditioned music from a text prompt. Inputs: prompt text, a genre selector (80s R&B or 90s Hip-Hop...

Generate sound effects from a text prompt. Takes a text description and optional duration (1–10 seconds) and outputs an...
Generate music from a text prompt. Produce up to 30 seconds of instrumental audio by describing genre, mood, tempo, key,...

Generates music from text prompts using a fine-tuned Stable Diffusion model that creates spectrograms which are then con...

Generate music from a text prompt. Accepts a natural-language description and a target duration (1–60 seconds) and outpu...
Generate music from a text prompt. Produce instrumental tracks and loops using a fine-tuned Stable Audio 2 model, with c...

Generate 30-second music from a text prompt. Accepts a prompt with optional negative prompt and seed, and outputs 48 kHz...
Generate audio from a text prompt. Produce sound effects, human speech, and music, with controls for clip duration and t...
Generate music from a text prompt. Control style by specifying genre, era (e.g., 90s, 80s), mood, and instruments, and a...
Generates music from text prompts describing genre, mood, instruments, and style. Accepts lyrics input or can create ins...

Generate music from text prompts with controllable musical features. Uses a Latent Diffusion Model combined with Flan-T5...
Generates music from text prompts with configurable style, title, and instrumental options.

Generates music from text prompts using a non-autoregressive transformer architecture. Offers multiple model sizes (300M...