lucataco/kosmos-2 🖼️✓❓ → ❓
Performance
About
Grounding Multimodal Large Language Models to the World
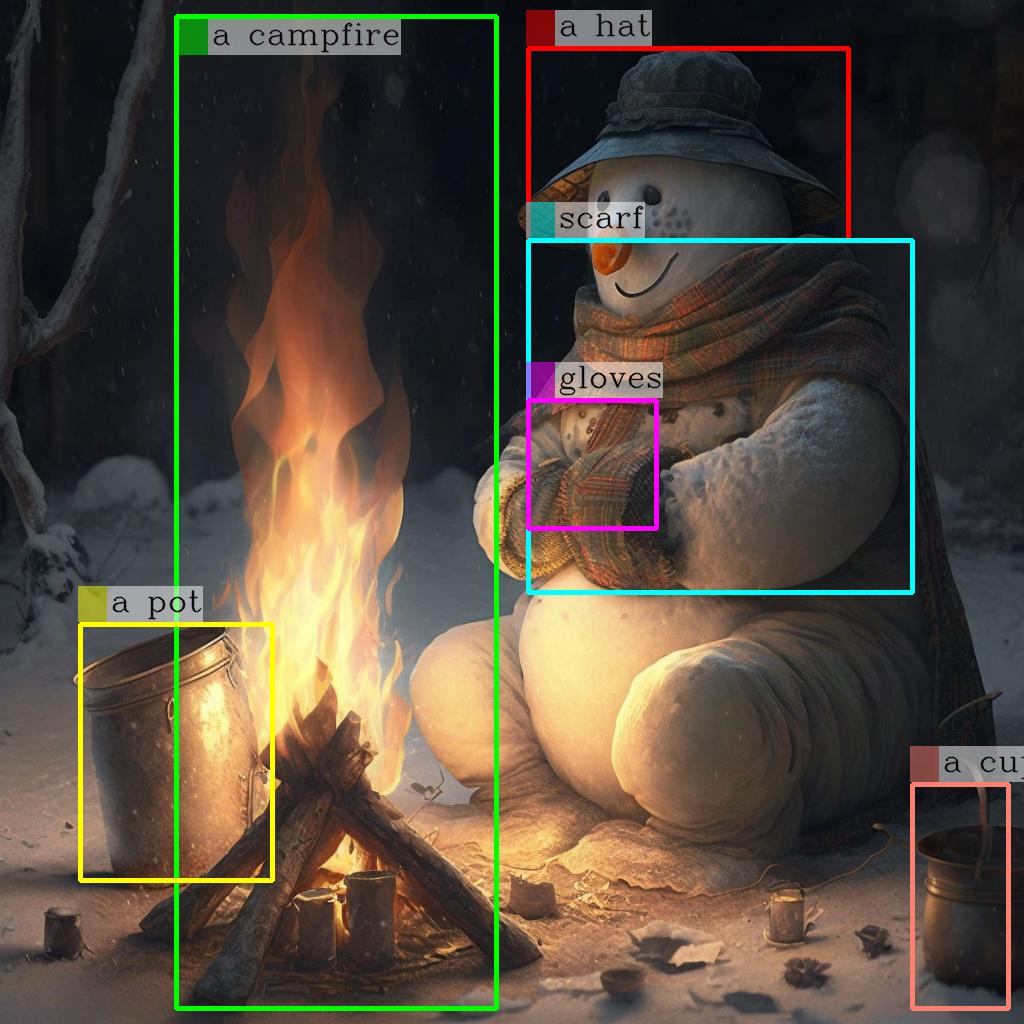
Example Output
Output
{"img":"https://replicate.delivery/pbxt/drgxiFZGotafKiDanUGbyvkg0kOUeADYiJu6UxthUWu2Qx0RA/output.jpg","text":"Describe this image in detail: The image features a snowman sitting by a campfire in the snow. He is wearing a hat, scarf, and gloves, with a pot nearby and a cup nearby. The snowman appears to be enjoying the warmth of the fire, and it appears to have a warm and cozy atmosphere.
{kind=link}
[('a campfire', (71, 81), [(0.171875, 0.015625, 0.484375, 0.984375)]), ('a hat', (109, 114), [(0.515625, 0.046875, 0.828125, 0.234375)]), ('scarf', (116, 121), [(0.515625, 0.234375, 0.890625, 0.578125)]), ('gloves', (127, 133), [(0.515625, 0.390625, 0.640625, 0.515625)]), ('a pot', (140, 145), [(0.078125, 0.609375, 0.265625, 0.859375)]), ('a cup', (157, 162), [(0.890625, 0.765625, 0.984375, 0.984375)])]"}
Performance Metrics
All Input Parameters
{
"image": "https://replicate.delivery/pbxt/JoIS31y9Oy2m04rBBICdzXUw7WleL1uCP6dyV5TeKTft2jjB/snowman.png",
"visual_output": true,
"description_type": "Detailed"
}
Input Parameters
- image (required)
- Input image
- visual_output
- Select to show the image with bounding boxes
- description_type
- Description Type
Output Schema
- img
- Img
- text
- Text
Version Details
- Version ID
d5098d8db2a801b45ca11451a0ce421e27353b0298fb3aeba4a9055bd67c582a- Version Created
- November 3, 2023