🤖 Model 🖼️ → 📝

nomagick/qwen-vl-chat
Generates text responses based on text prompts and images with ChatML prompt interface and streaming support. Accepts up...
Found 40 models (showing 1-20)
Generates text responses based on text prompts and images with ChatML prompt interface and streaming support. Accepts up...

Detect objects in images using natural language queries. Accepts an image and comma-separated text queries (category nam...
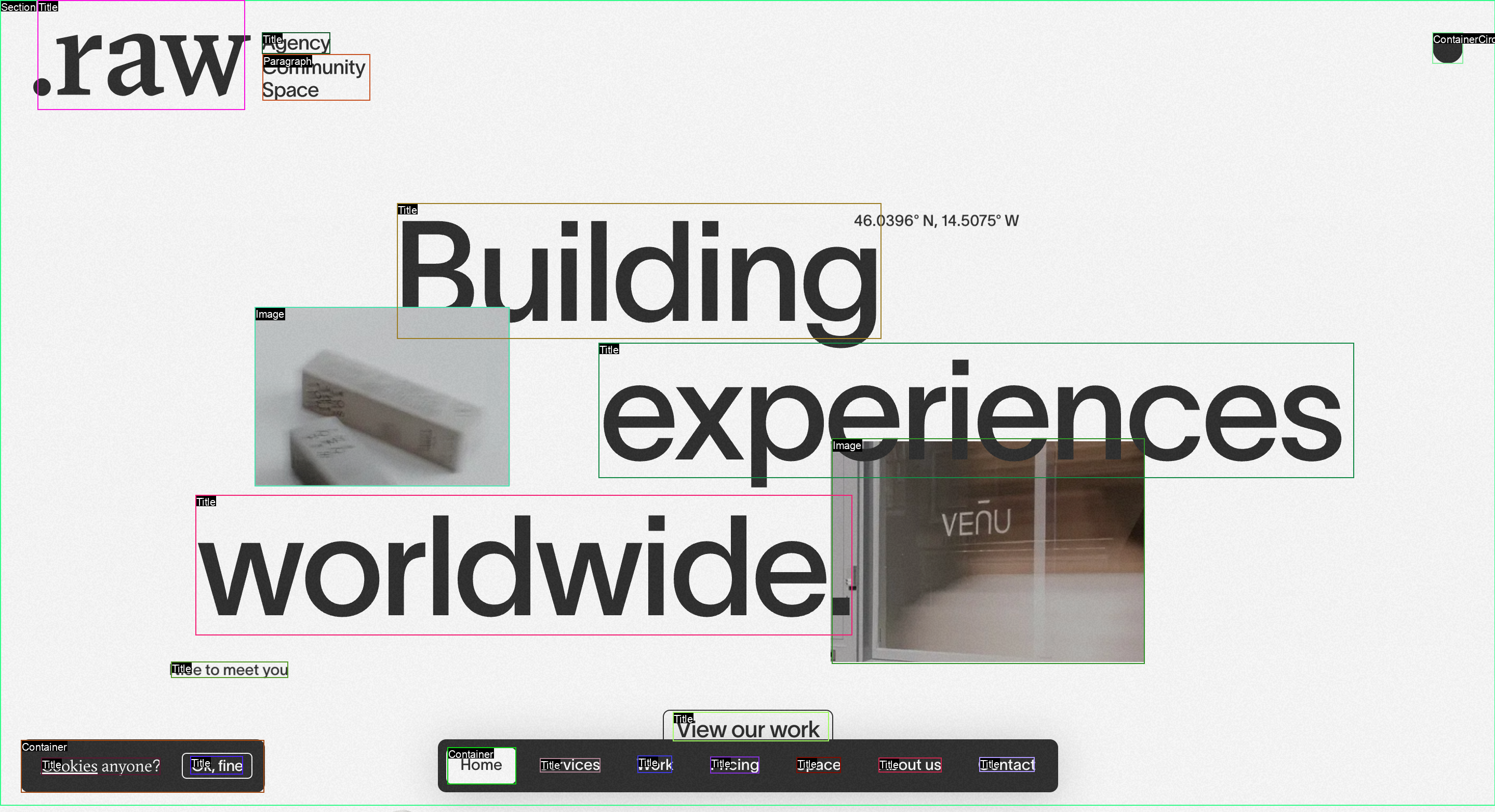
Detect objects in an input image and return an annotated image with bounding boxes, class labels, and optional confidenc...

Detect and localize vehicle damage from an input image, returning an annotated image that highlights affected areas for...
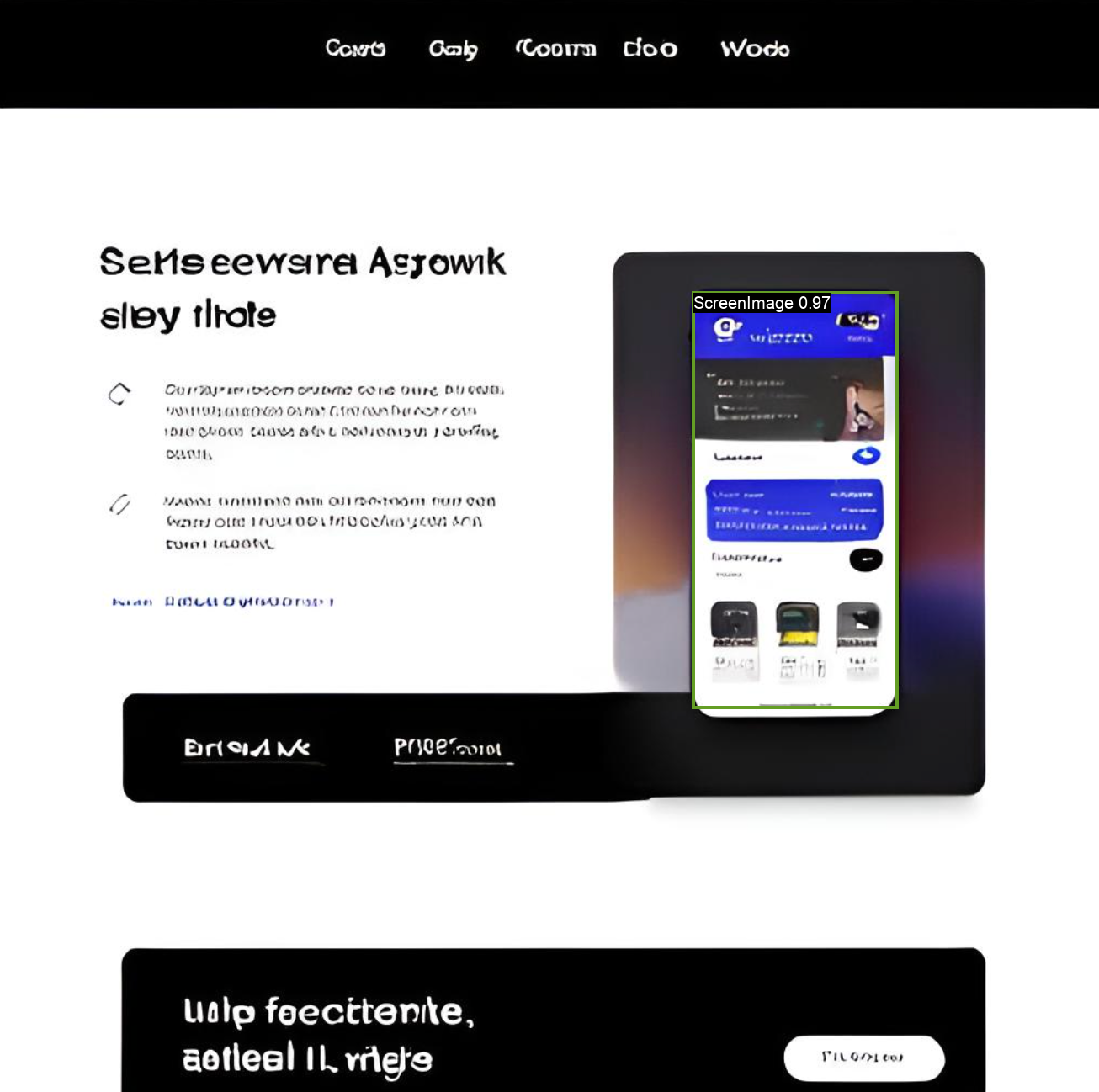
Detect user interface elements in screenshots and app/web screens, returning an annotated image with bounding boxes, lab...
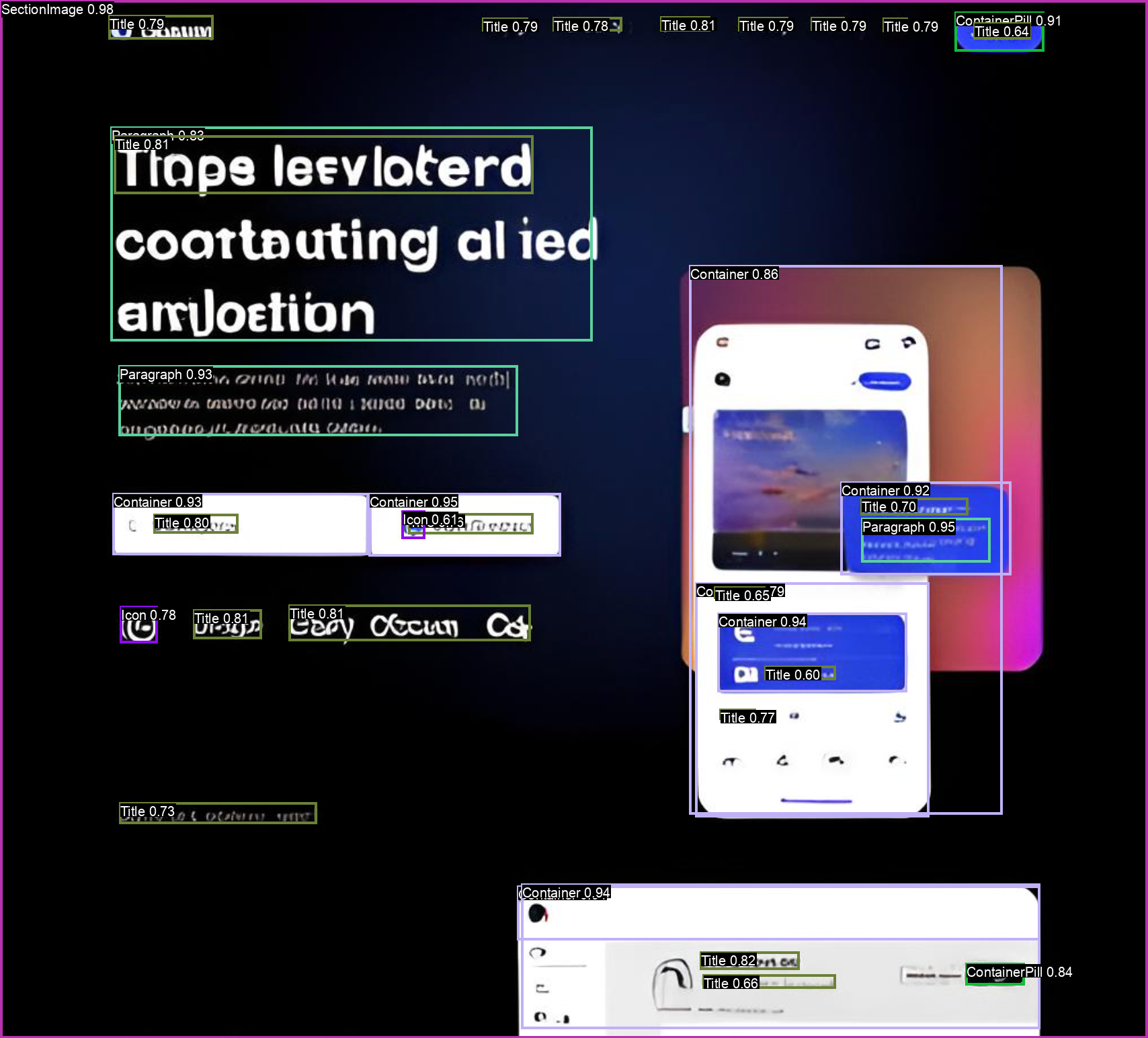
Detect UI layout sections and components in screenshots. Takes an input image of a webpage or app interface and returns...
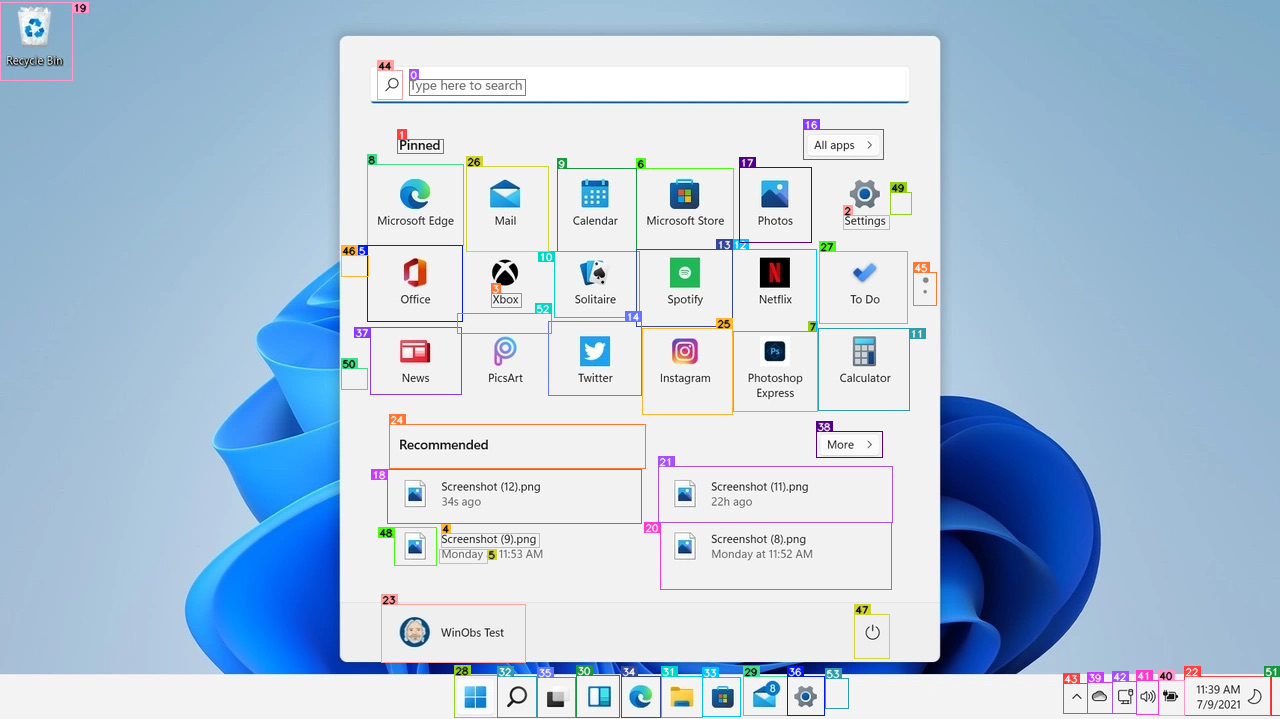
Parse GUI screenshots into structured UI elements with bounding boxes and captions. Accepts an image of a desktop or mob...

Automate GUI interactions by predicting where to click from a screenshot and a natural-language command. Takes a GUI scr...
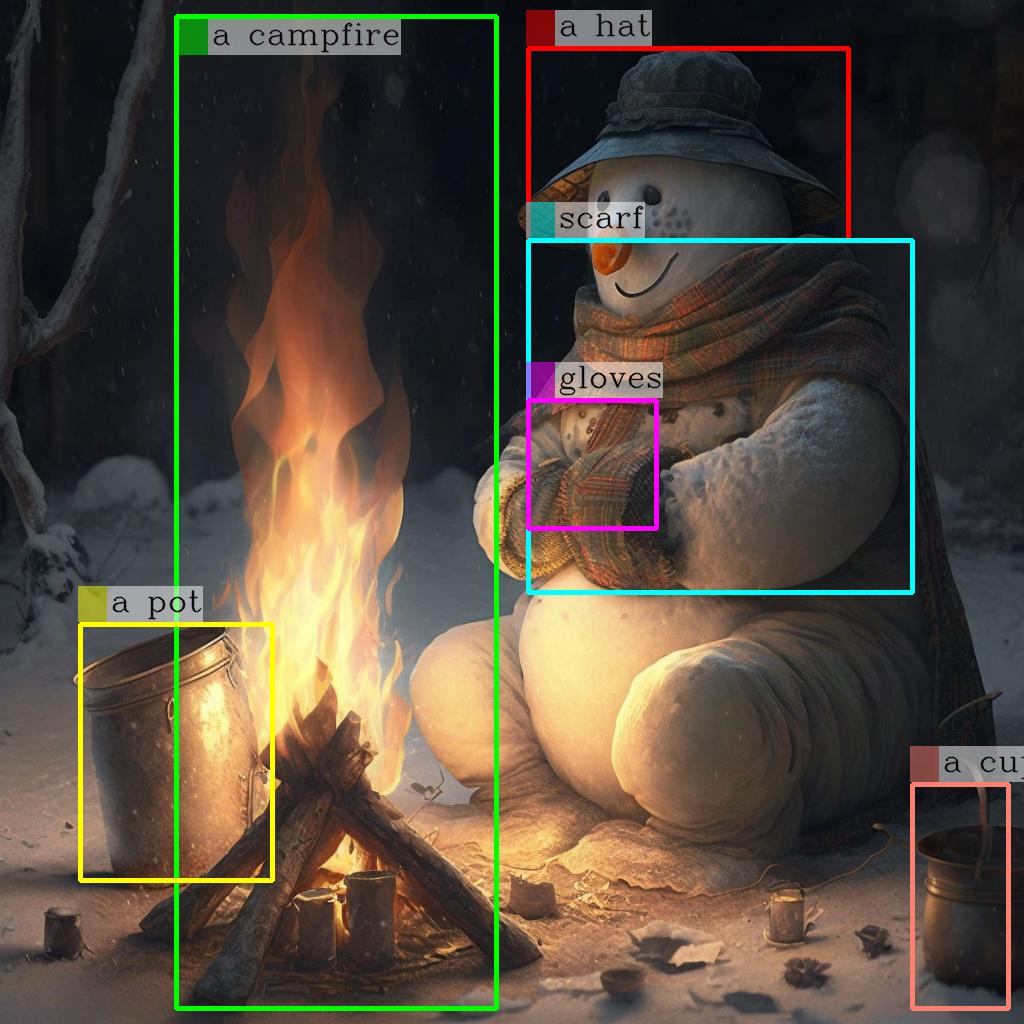
Caption images with grounded object localization. Take an image as input and return a brief or detailed natural-language...
Performs multiple computer vision tasks on images including captioning, object detection, OCR, and segmentation. Takes a...
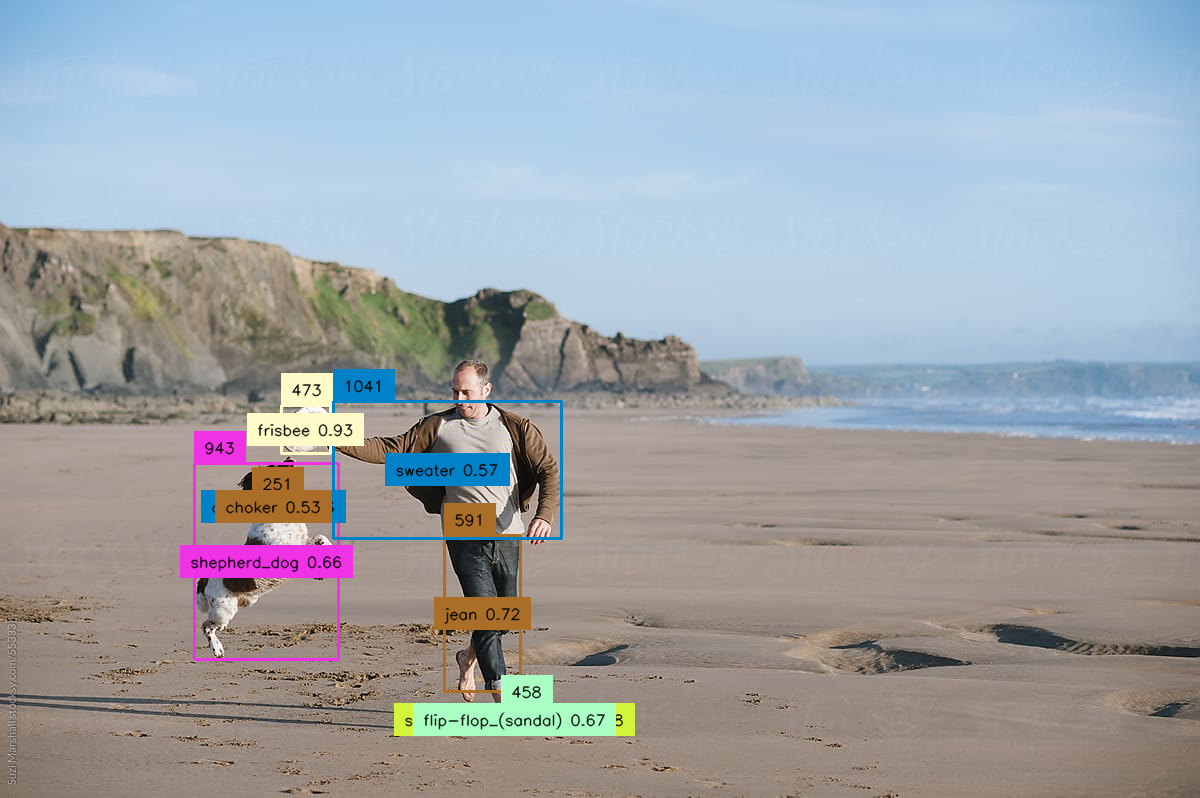
Detect objects in images and return bounding boxes, class names, and confidence scores. Accepts an image input and outpu...

Tag and segment objects in images, returning labels, bounding boxes, and pixel masks. Accepts an image as input and outp...

Execute computer vision tasks from natural-language instructions on an input image and return an image that visualizes t...

Detect anime faces in images. Accepts an input image and returns YOLO-format face bounding boxes (class id, x_center, y_...

Performs multiple vision and vision-language tasks based on text prompts. Supports image captioning with varying detail...

Analyze images to generate captions, detect objects, and extract text (OCR). Accepts an image plus a task selector and o...
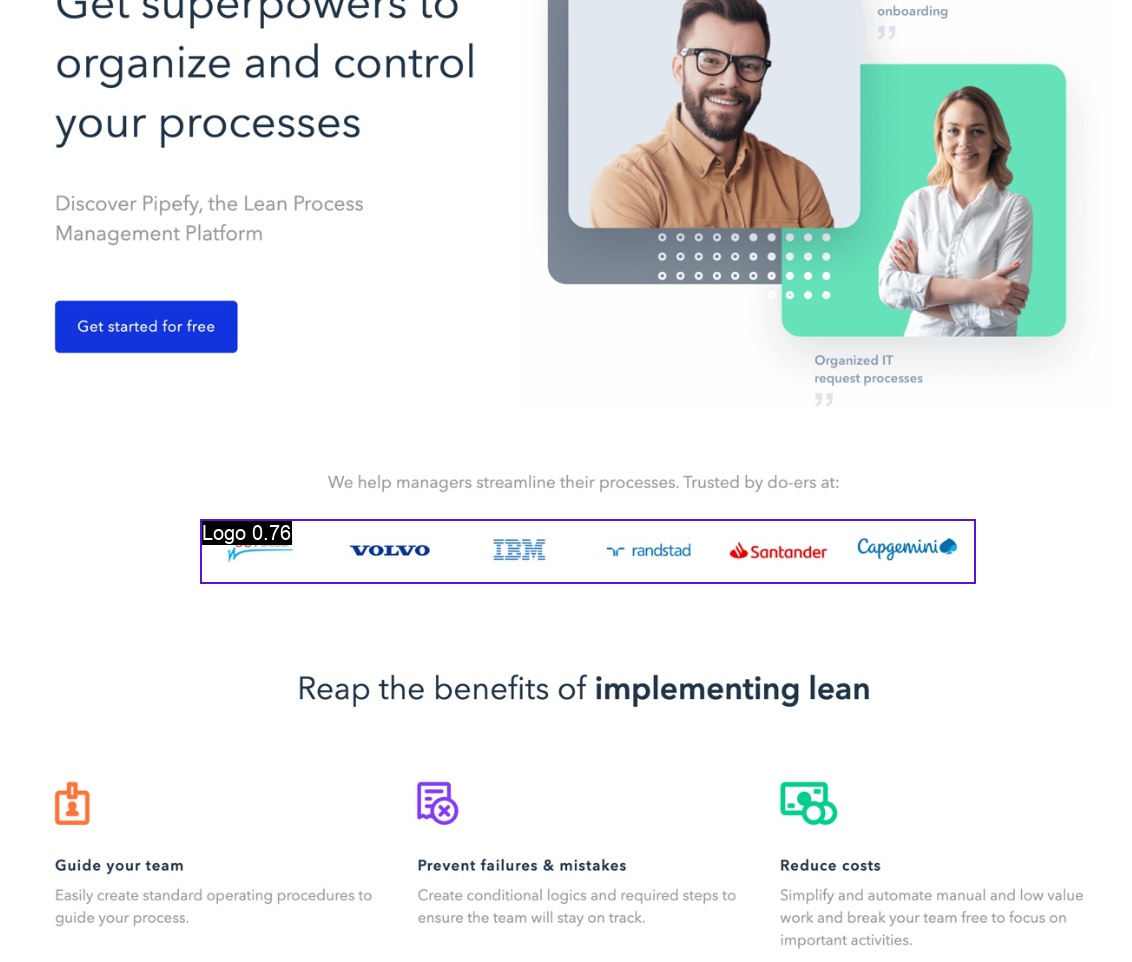
Detect logos in images and return an annotated image. Configure detection score threshold and IoU filtering, toggle labe...

Detect objects in an image using free-form text queries (zero-shot, open-vocabulary). Accepts an image and a comma-separ...
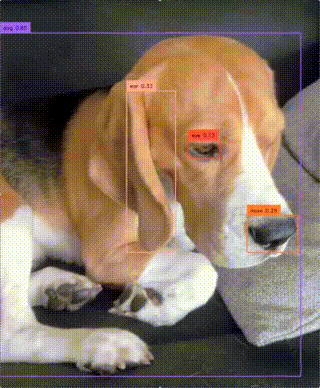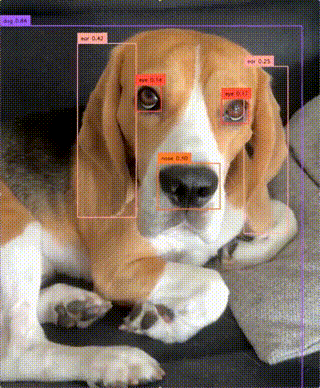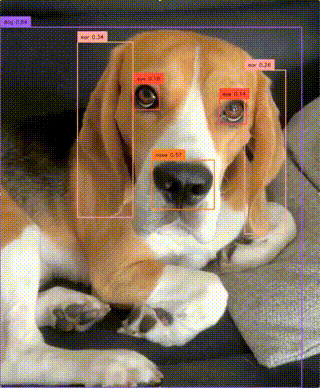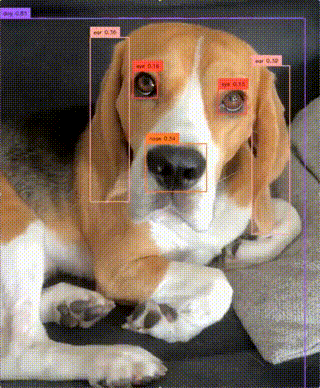
Detect objects from arbitrary, user-defined categories in images and videos in real time. Takes an image or video plus a...

Generate panoptic scene graphs from an input image. Segment both “things” and “stuff” at pixel level, detect objects and...