🤖 Model
bytedance/dolphin
Convert PDFs or document images into Markdown or structured JSON with layout-aware OCR and element parsing. Perform page...
Found 21 models (showing 1-20)
Convert PDFs or document images into Markdown or structured JSON with layout-aware OCR and element parsing. Perform page...

Convert scanned or digital documents to Markdown. Accepts PDF, EPUB, MOBI, XPS, and FB2 inputs and outputs Markdown plus...

Extract structured data from receipt images into JSON. Input a receipt image; output structured key–value fields and lin...

Extracts personally identifiable information (PII) from text input, specifically trained to recognize Indian names and a...

Extract structured document layout and text from an image input and return a single JSON output. Parse page elements wit...

Extract structured data from web pages into JSON. Accept a URL or raw HTML plus natural-language element prompts, scope...
Extract entities and relationships from Spanish legal text into structured JSON for knowledge graph construction and leg...

Extract text and document metadata from PDF pages, returning structured JSON. Accepts a PDF and page number, then transc...

Extract text and structured data from images and multi-page PDFs using visual OCR and layout analysis. Accept an image o...
Link entities in text to Wikipedia pages. Accepts text and returns disambiguated entity mentions with start/end characte...
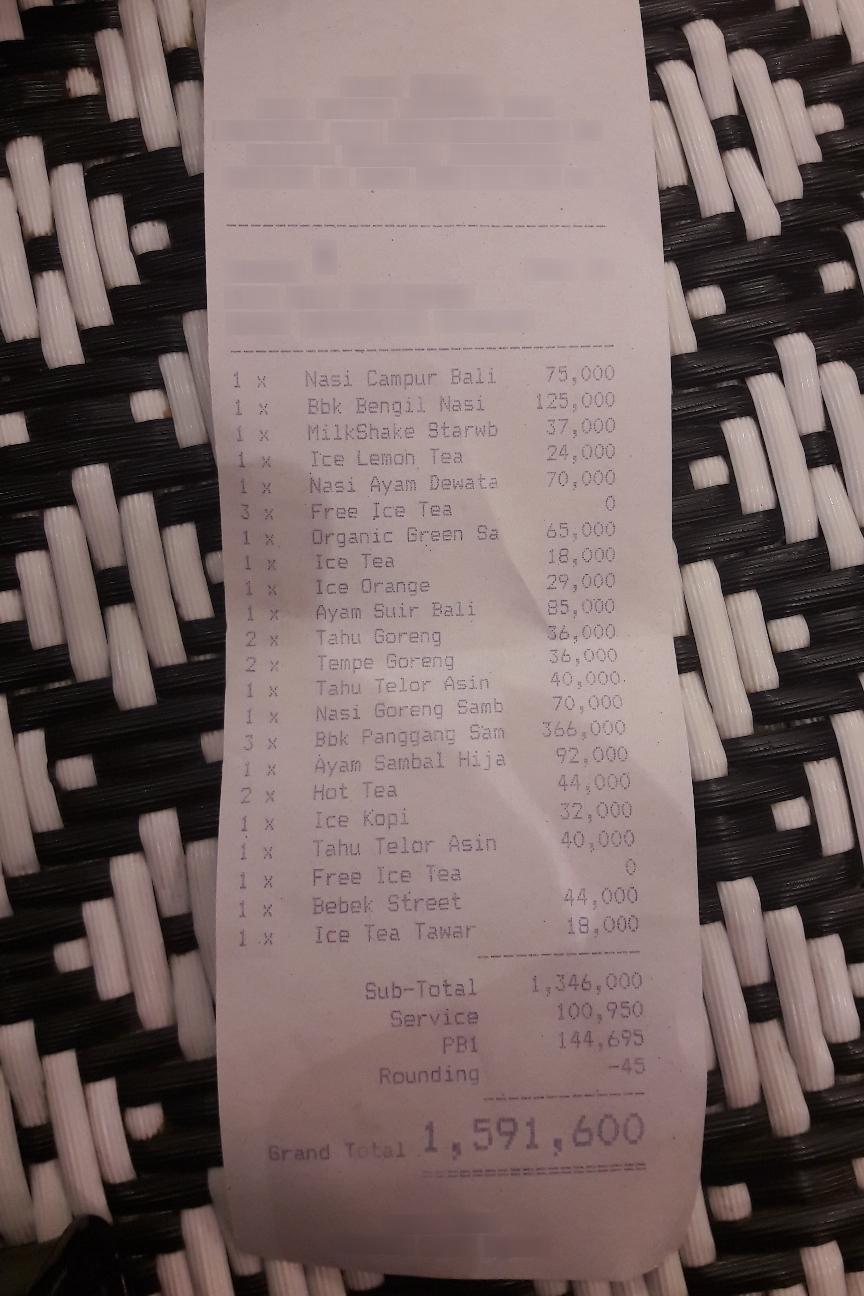
Extract structured purchase data from receipt images as JSON. Input a receipt image and output JSON with line items, qua...
Convert documents to Markdown and structured JSON. Accept PDF, DOC/DOCX, PPT/PPTX, and image files (PNG/JPG/WEBP) as inp...
Extracts text from images using Microsoft's Florence-2-Large model, optimized for high-throughput document OCR processin...

Generate text from prompts with configurable reasoning effort and verbosity for complex professional work, coding, and m...

Generate text content with structured outputs, web search capabilities, and custom tools based on text prompts and image...

Converts arXiv papers into a single, expanded LaTeX file for processing by Large Language Models. Takes an arXiv URL as...
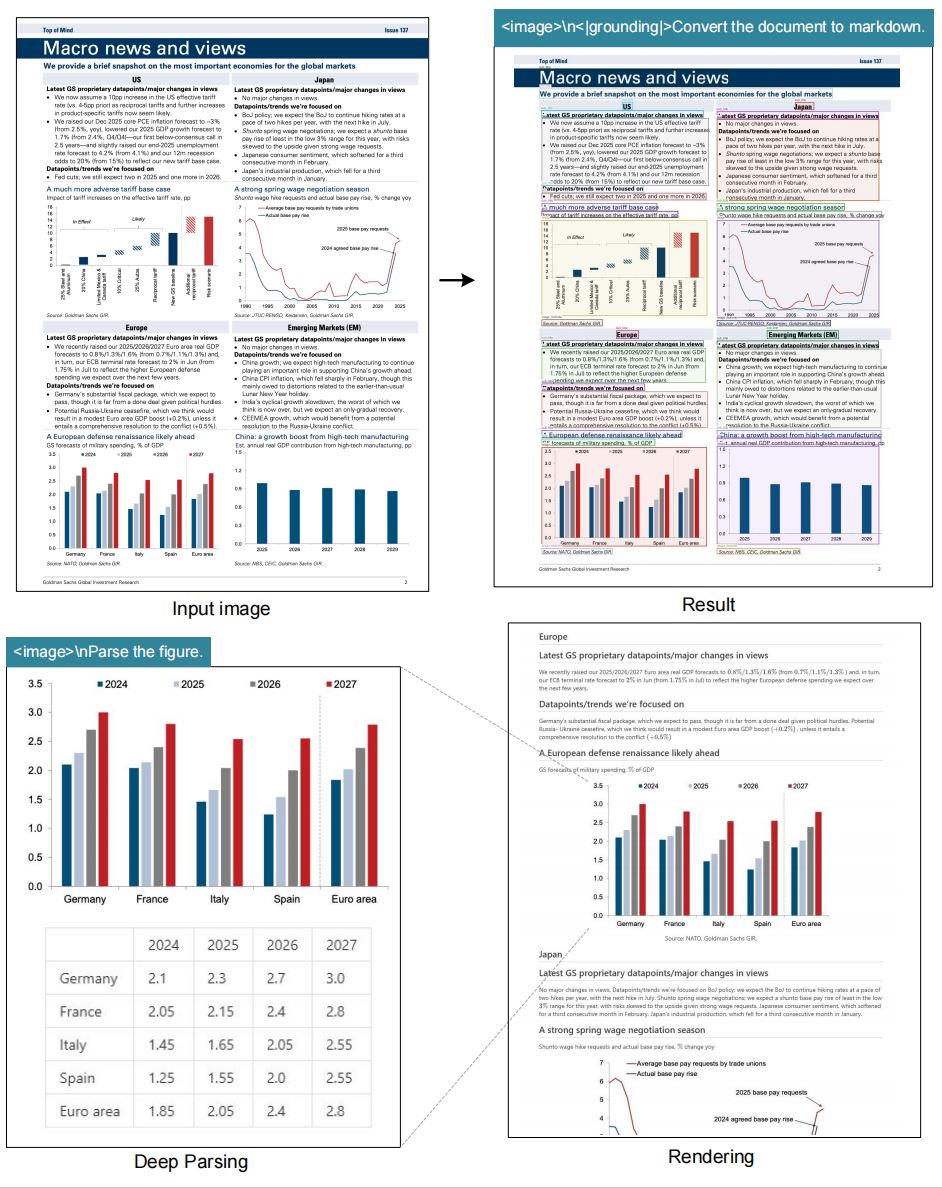
Extract text and convert documents to markdown format from images using optical character recognition. Supports multiple...

Converts images containing documents, PDFs, charts, and handwritten text into structured markdown while preserving forma...

Generates text responses based on text prompts and images with ChatML prompt interface and streaming support. Accepts up...

Analyzes images and videos to answer questions, extract data, and provide detailed descriptions. Supports processing up...