🤖 Model 🖼️ → 📝

bytedance/sa2va-26b-image
Segment objects in images from natural-language instructions and answer visual questions. Provide an image plus a text i...
Found 59 models (showing 1-20)
Segment objects in images from natural-language instructions and answer visual questions. Provide an image plus a text i...

Analyzes images with text instructions to provide visual understanding and object segmentation. Combines SAM2 segmentati...

Segment objects and regions in images using natural language instructions. Accepts an image and a text instruction and r...

Segment objects in images from a bounding box prompt, returning an image with the selected region outlined or masked. Us...

Encode images using the SAM (Segment Anything) ViT-H model, which is designed for image segmentation tasks.

Segment objects in images using natural language prompts. Accepts an input image and a text prompt describing the target...

Segment hair in images. Takes a single image as input and outputs an image segmentation mask that isolates hair pixels....

Segment clothing and optionally faces in images and output a binary mask. Adjust mask tightness with erosion/dilation co...

Segment garments in images. Accepts an input image and a clothing category (topwear or bottomwear), and returns a binary...

Segment clothing in an image and output a mask for the selected region (upper, lower, or full body). Accepts a single im...

Segment clothing in an input image and output a refined binary mask. Select top or bottom via ootd_type, with automatic...
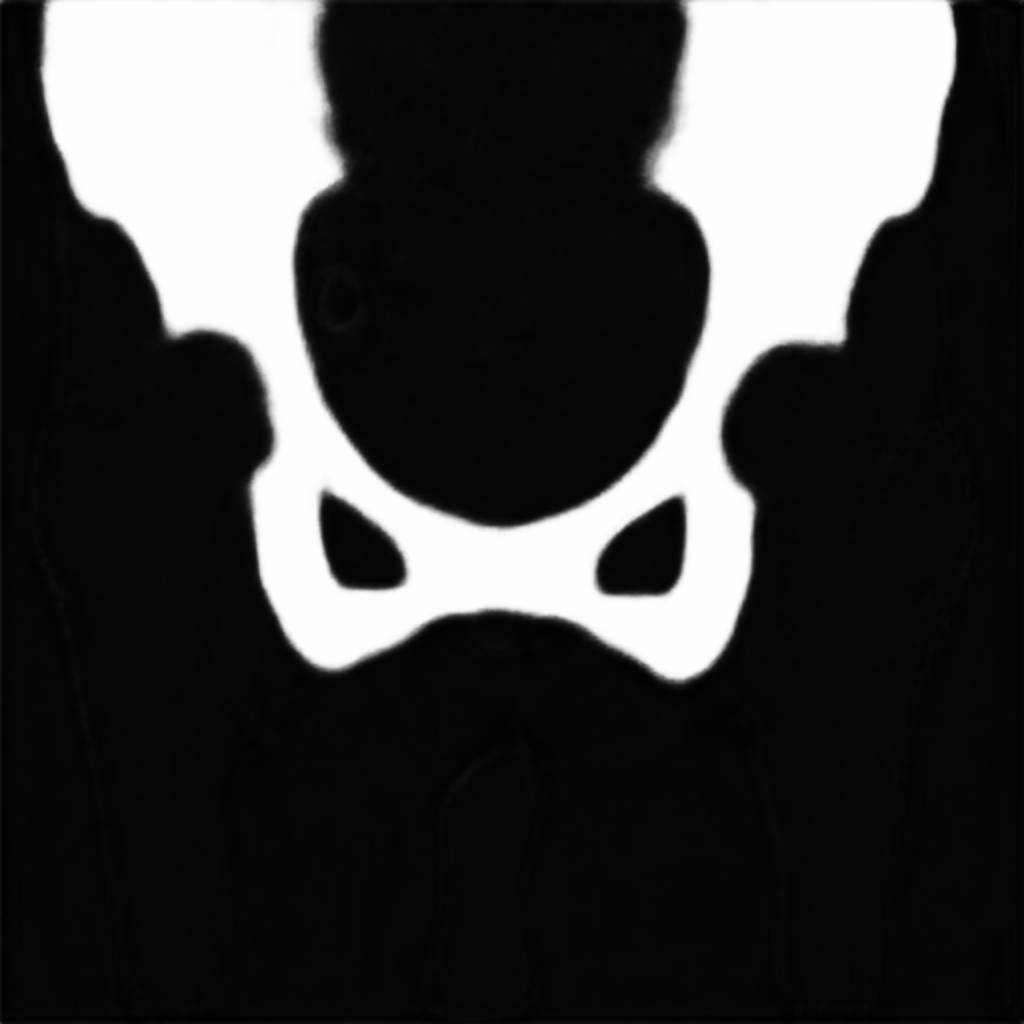
Segment the pelvis/hip in radiographic X-ray images. Takes a single X-ray image as input and returns a per-pixel probabi...

Segment images into labeled regions and object classes. Takes an image as input and outputs a color-coded segmentation m...

Segment islands and coastlines in images. Takes a single image as input and outputs a segmentation mask highlighting lit...

Refine satellite-derived shorelines from a satellite image and a shoreline mask, outputting a refined shoreline visualiz...

Generate part-aware 3D assets from a single input image. Segment the object into semantic parts, optionally merge segmen...
Segment roads in images. Accepts a single image and outputs an image with road regions highlighted as a segmentation mas...

Detect glare on cards in photos. Accepts a single image and returns a segmentation mask highlighting glare regions, supp...

Remove image backgrounds from a single image input. Outputs a foreground cutout and a binary segmentation mask. Uses Dic...

Remove backgrounds from images. Takes a single image as input and outputs an image with the background removed, isolatin...