🤖 Model 🖼️ → 📝

cjwbw/cogvlm
Analyzes images and answers questions about them using a visual language model. Takes an image and a text query as input...
Found 174 models (showing 21-40)
Analyzes images and answers questions about them using a visual language model. Takes an image and a text query as input...

Answers questions about images through multimodal understanding. Takes an image and a text question as input and generat...

Analyze images and videos with text prompts to generate detailed text responses. Handles single images, multiple images,...
Caption images and answer questions about images. Takes an image and a text prompt as input and returns text, enabling i...

Analyzes images and generates text descriptions or answers questions about visual content. Uses a projection module trai...

Analyzes images and generates text responses to questions about the visual content. Takes an image and text prompt as in...

Analyzes images and answers questions about visual content with enhanced reasoning capabilities. Takes an image and text...

Analyzes images and responds to text prompts about visual content. Takes an image and a text prompt as input, then gener...

Accepts arbitrary sequences of image and text inputs to produce text outputs for multimodal tasks. Answers questions abo...

Answers questions about images using natural language. Takes an image and text prompt as input and generates contextual...

Extract text from images and PDFs in 90+ languages. Accept an image or multi-page PDF, a selected language list, and a p...
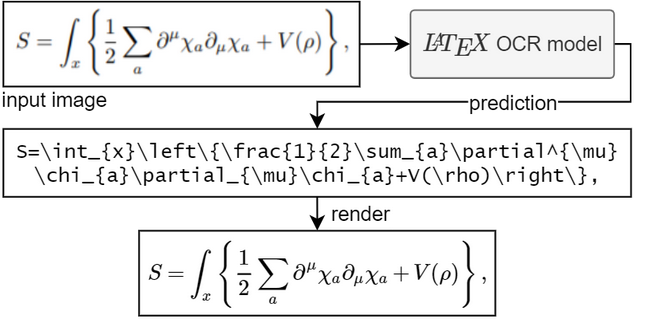
Extract LaTeX code from images of mathematical equations and expressions. Takes a single image as input and returns the...

Analyze documents and images from one or more image inputs plus a text prompt, returning text captions, OCR, and answers...
Converts images into text descriptions or captions.

Analyzes images and generates descriptive tags with confidence scores. Takes an image as input and returns an array of t...

Analyzes images and answers questions about them using a unified autoregressive framework for multimodal understanding....

Extract structured document layout and text from an image input and return a single JSON output. Parse page elements wit...
Answers questions about images and generates detailed captions based on visual content and text prompts. Processes both...

Generates text prompts from input images that can be used with Stable Diffusion to recreate similar-looking versions of...
Analyzes images and generates text responses based on visual content and text prompts. Accepts arbitrary sequences of im...