🤖 Model
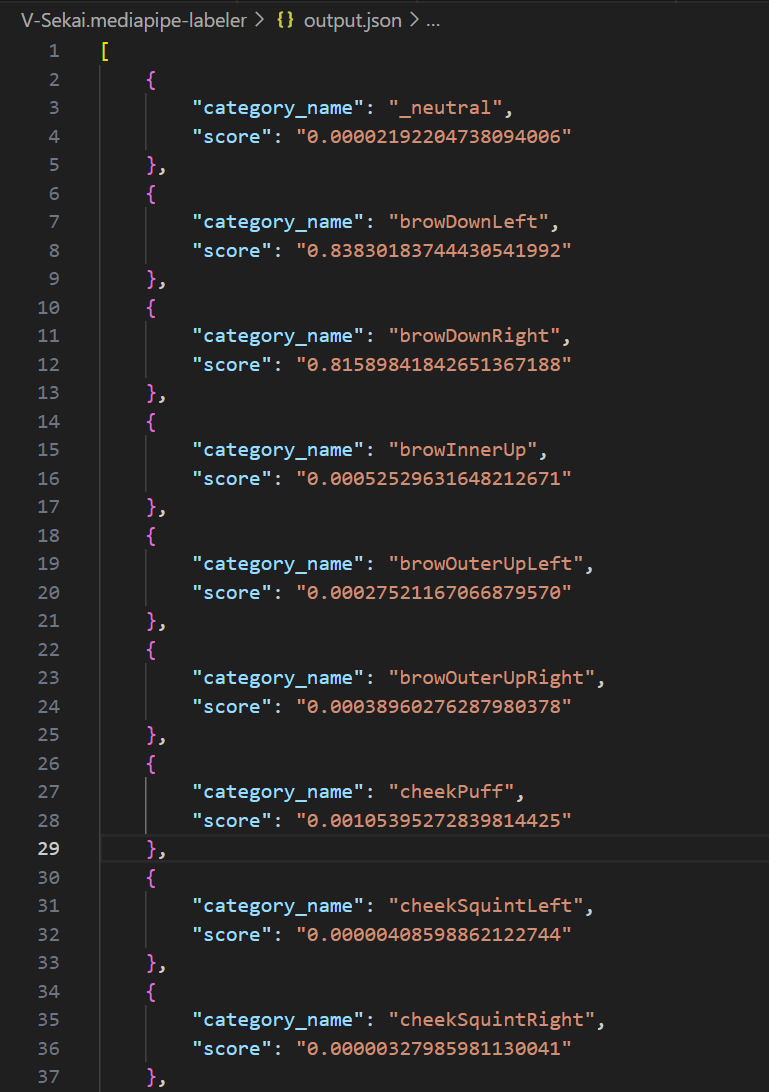
fire/v-sekai.mediapipe-labeler
Label facial blendshapes and pose keypoints from images or videos. Detect up to 1–100 people and return per-frame JSON a...
Found 14 models (showing 1-14)
Label facial blendshapes and pose keypoints from images or videos. Detect up to 1–100 people and return per-frame JSON a...
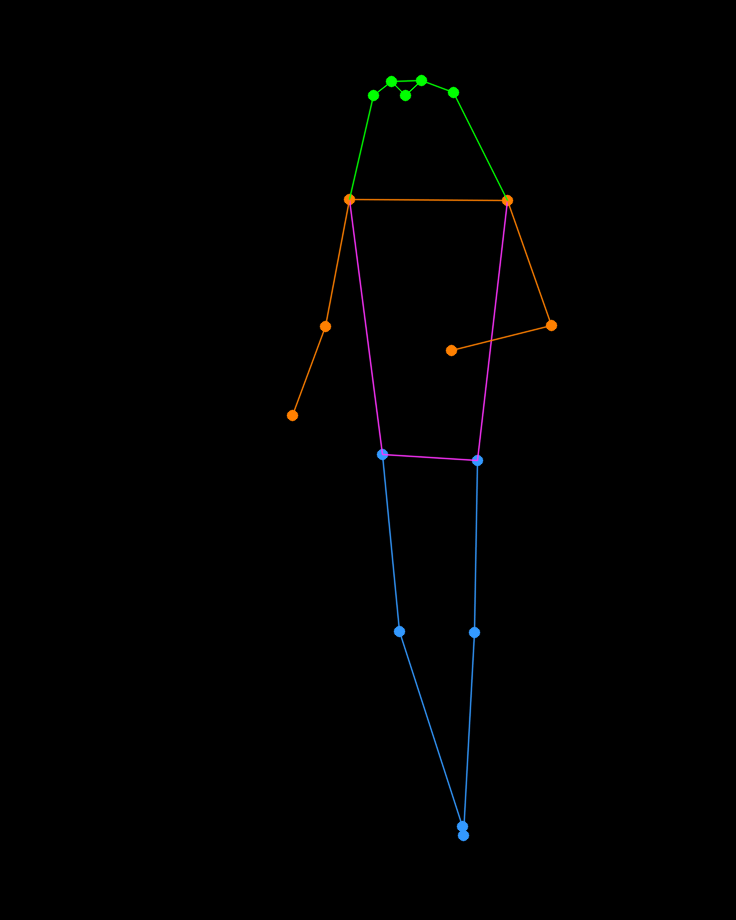
Estimate human poses in images and output an image annotated with keypoints and skeletons. Uses Ultralytics YOLOv11 Pose...
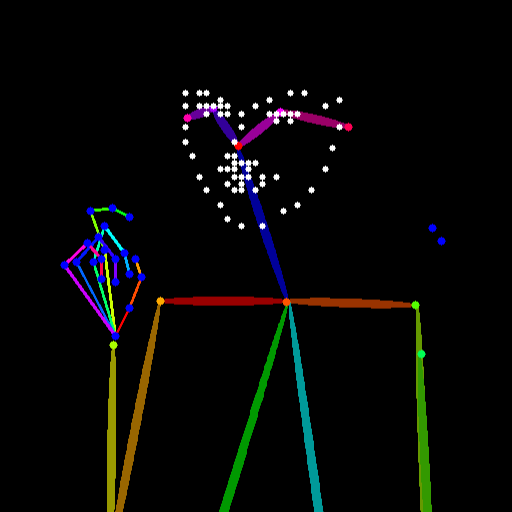
Estimate human pose from an input image and output an OpenPose-style pose map image. Optionally include facial landmarks...

Estimate human body pose from an input image, returning 2D keypoint coordinates for each detected person. Leverage YOLO-...

Detect human pose skeletons from an image and output a colored OpenPose-style visualization. Extract 25 body keypoints,...

Convert videos to DensePose representations. Takes a video as input and outputs a video visualizing per-frame DensePose...
Estimate human pose from images or videos and return a visualized 2D skeleton (OpenPose-style) as an image or video. Ren...
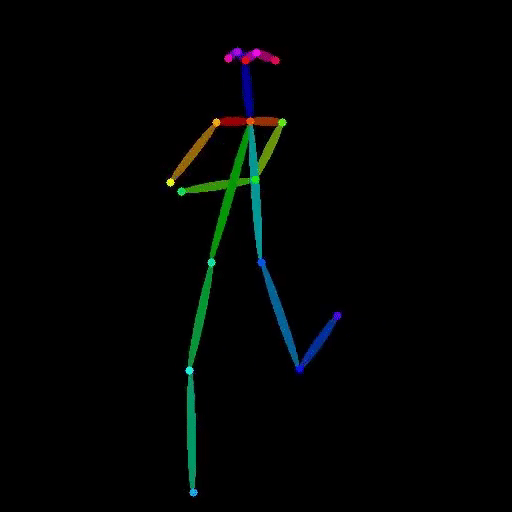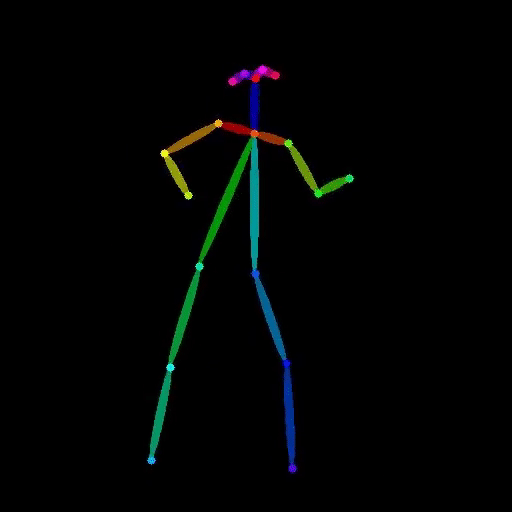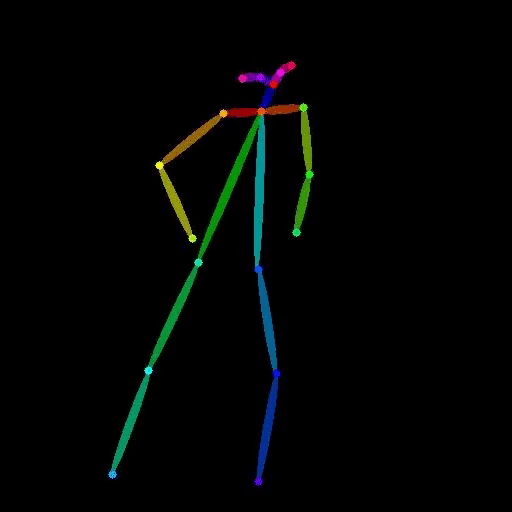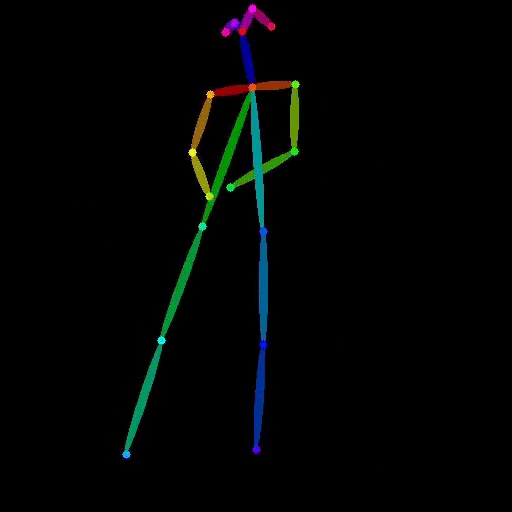
Extract human pose from a video and output an OpenPose-style skeleton video. Provide a video as input and receive a vide...

Estimate 2D poses of multiple people in an image using a lightweight version of OpenPose. Outputs include 18 keypoints p...

Generate DensePose UV and segmentation maps from an image or video to create driving poses for MagicAnimate and other mo...
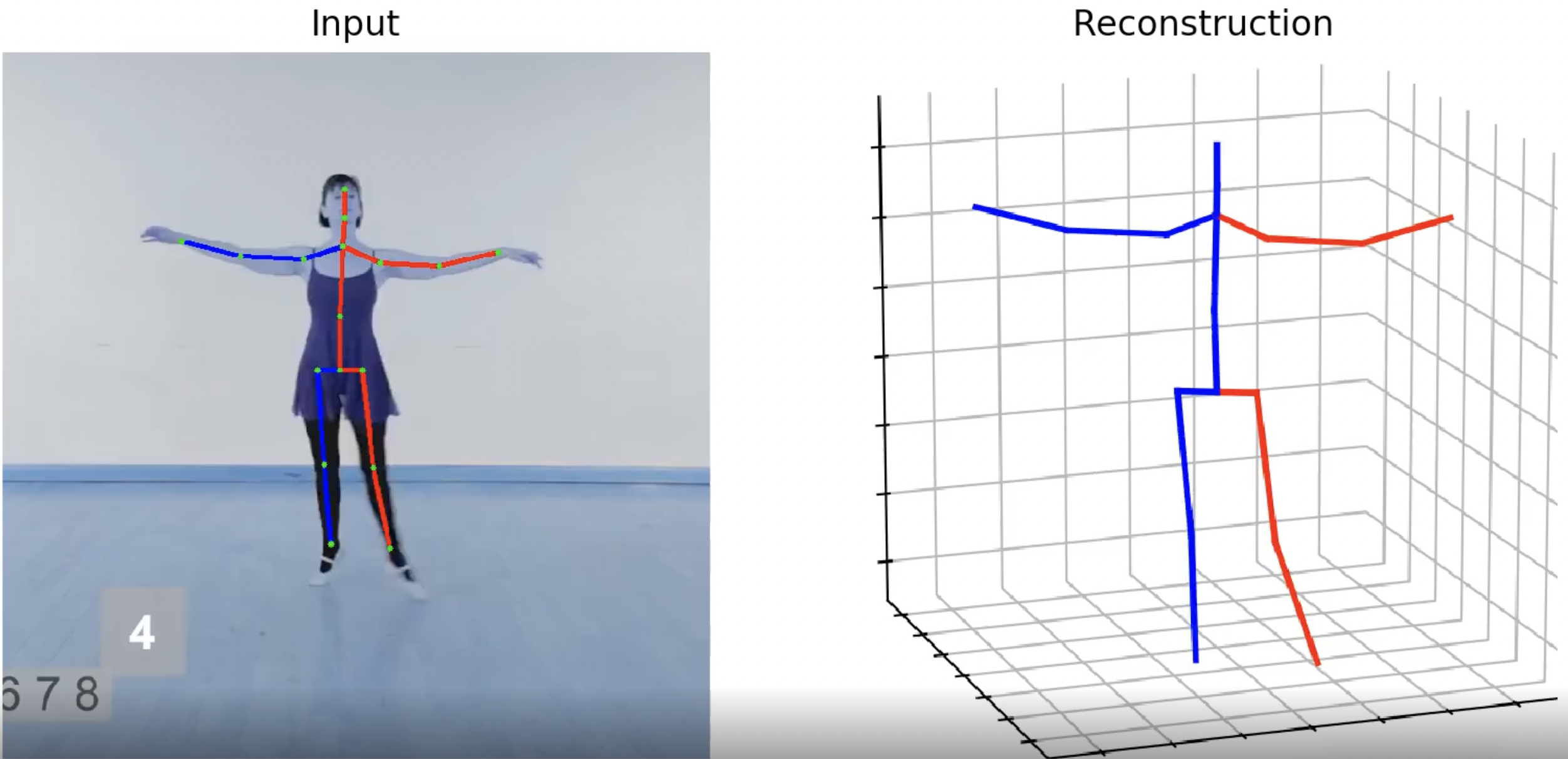
Estimate 2D and 3D human pose from a single-person image or short video. Return a visualization video with skeletal over...

Generate ControlNet conditioning maps from an input image. Run multiple preprocessors simultaneously and return images f...
Generates videos of virtual humans by transferring poses from an input video to a reference person image. Takes a refere...

Generates images from text prompts using Stable Diffusion XL with ControlNet conditioning. Supports pose-guided generati...