🤖 Model 🖼️

sljeff/dots.ocr
Extract structured document layout and text from an image input and return a single JSON output. Parse page elements wit...
Found 69 models (showing 21-40)
Extract structured document layout and text from an image input and return a single JSON output. Parse page elements wit...
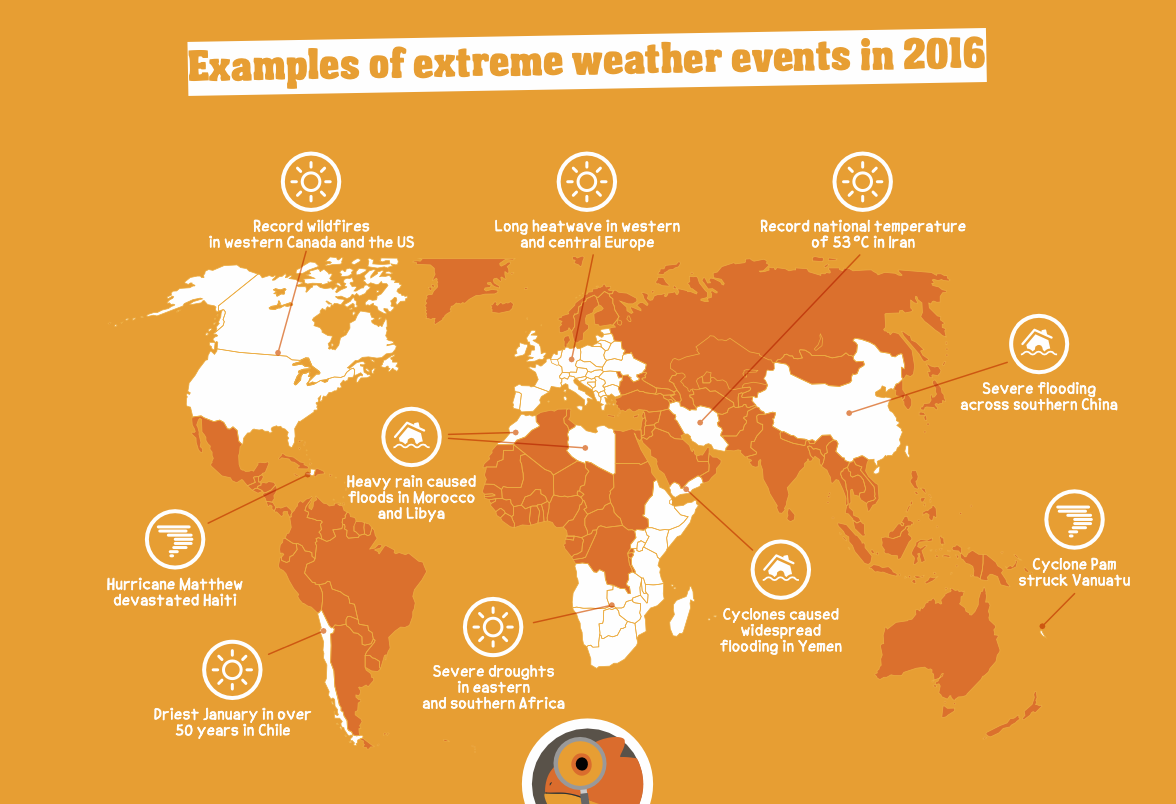
Analyzes images and generates text responses based on visual content and text prompts. Accepts arbitrary sequences of im...
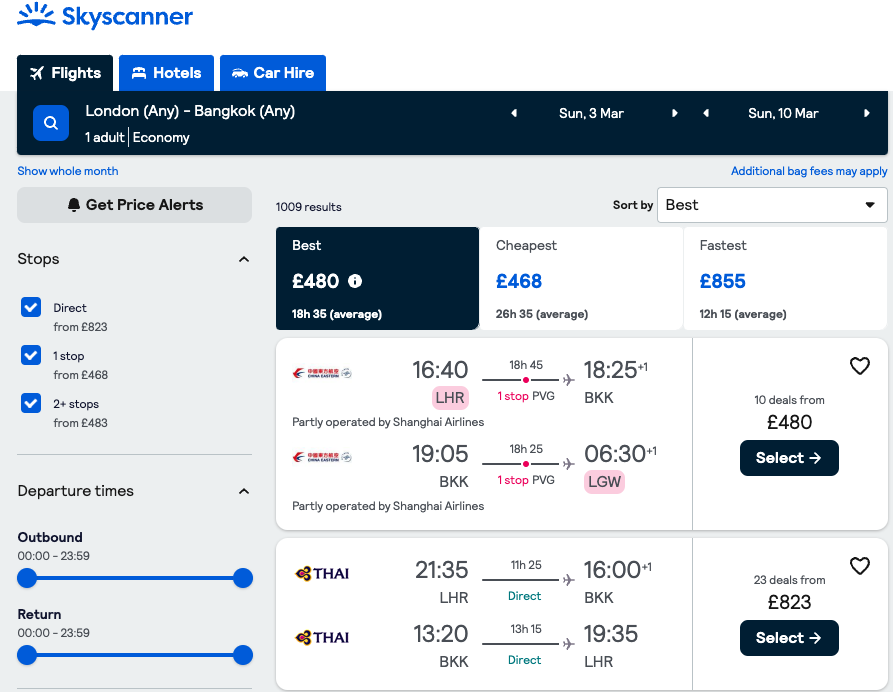
Answer questions about images and GUI screenshots. Takes an image and a natural-language query and returns a text respon...

Analyzes images and generates text responses based on prompts and visual content. Built on Google's PaliGemma 3B archite...

Convert PDFs, Office files, images, audio, HTML, and structured data to Markdown for LLM ingestion, indexing, and analys...
Convert PDFs to Markdown with optional OCR for scanned documents. Accepts a PDF and a method setting (auto, txt, or ocr)...

Answer questions about images. Takes an image and a text prompt and returns a text response, enabling visual question an...

Answer questions about images from a text prompt, returning a text response. Accepts an input image and a prompt and out...
Extract text from PDF documents. Accepts a PDF URL and returns plain text by converting each page to an image and runnin...

Extract text and document metadata from PDF pages, returning structured JSON. Accepts a PDF and page number, then transc...

Extract text and structured data from images and multi-page PDFs using visual OCR and layout analysis. Accept an image o...

Extract text from images or PDFs using OCR. Accepts an image or PDF plus a language selection (English “eng” or Arabic “...
Performs multiple computer vision tasks on images including captioning, object detection, OCR, and segmentation. Takes a...
Extract text from images with optional layout-preserving HTML reconstruction. Accept a single image and output plain tex...

Extract text from images (OCR). Accepts an image and an optional language setting (default Chinese) and returns structur...

Recognizes and extracts text from images of handwritten text, outputting the detected text as a string.

Convert images or PDFs containing mathematical notation into Markdown/LaTeX text. Accept an image input and return a tex...

Extract text with pixel coordinates from images and screenshots. Accepts an image and returns readable text (markdown) p...
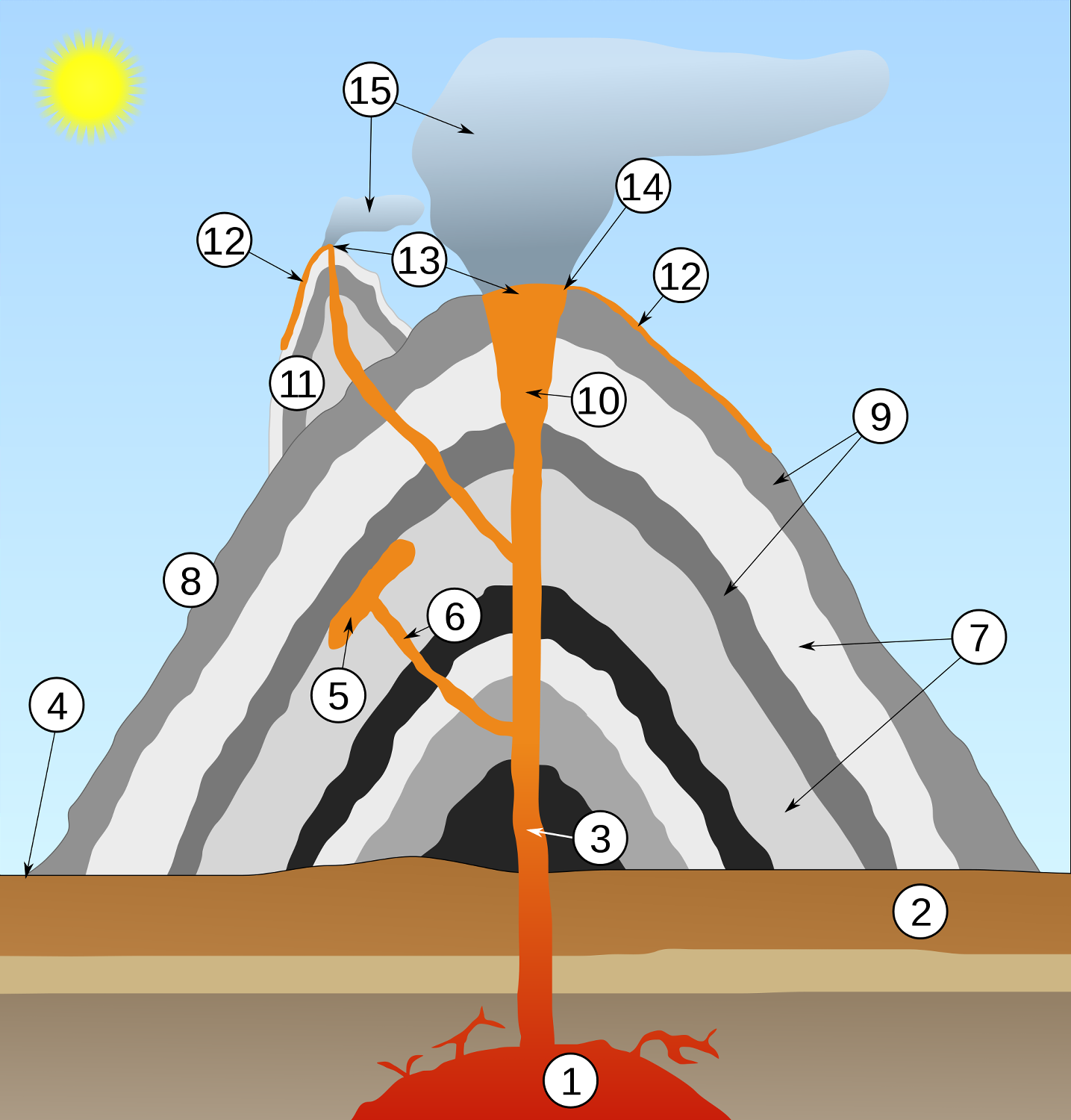
Analyzes images and answers questions or generates captions based on textual prompts. Provides six specialized models tr...

Analyzes images and generates text descriptions based on visual content and optional prompts. This small vision language...