🤖 Model 🖼️ → 📝

jyoung105/moondream
Answer questions about images from a text prompt, returning a text response. Accepts an input image and a prompt and out...
Found 174 models (showing 81-100)
Answer questions about images from a text prompt, returning a text response. Accepts an input image and a prompt and out...
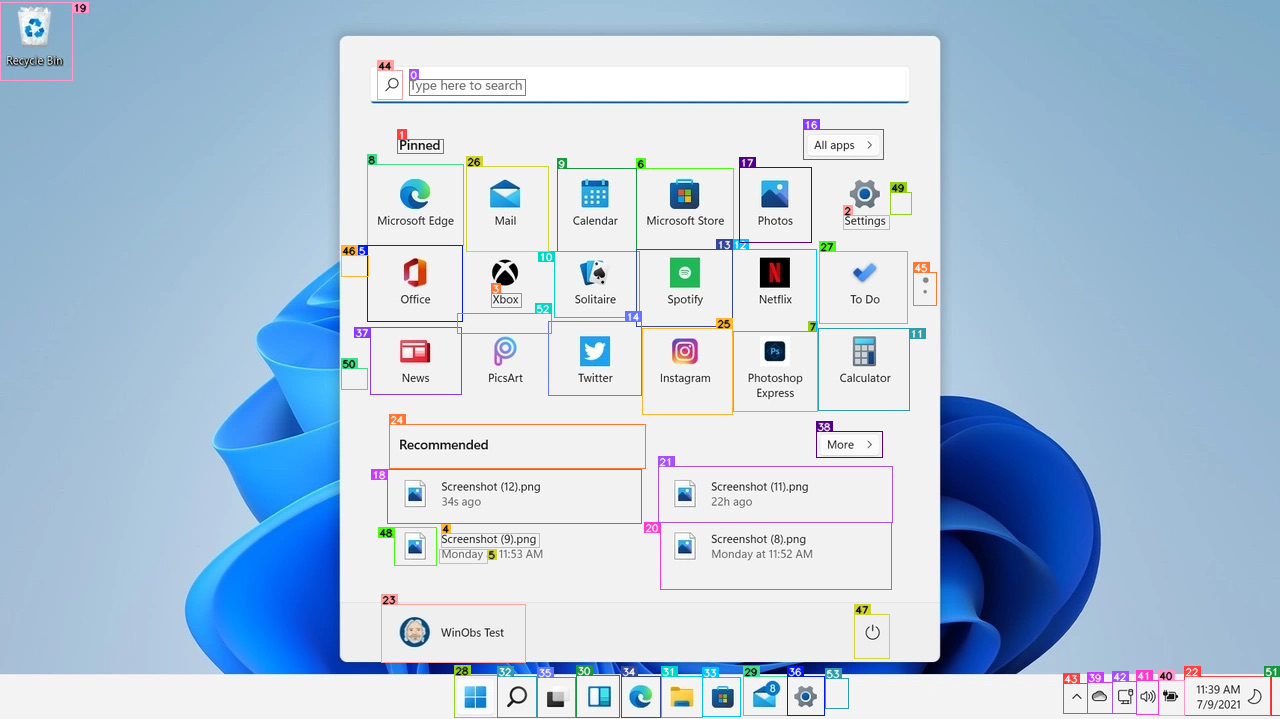
Parse GUI screenshots into structured UI elements with bounding boxes and captions. Accepts an image of a desktop or mob...
Extracts text and information from images using Google Lens functionality, taking an image as input and returning extrac...

Generates text responses based on image and text prompts using a multi-modal transformer architecture. Takes an image an...

Extract text and structured data from images and multi-page PDFs using visual OCR and layout analysis. Accept an image o...
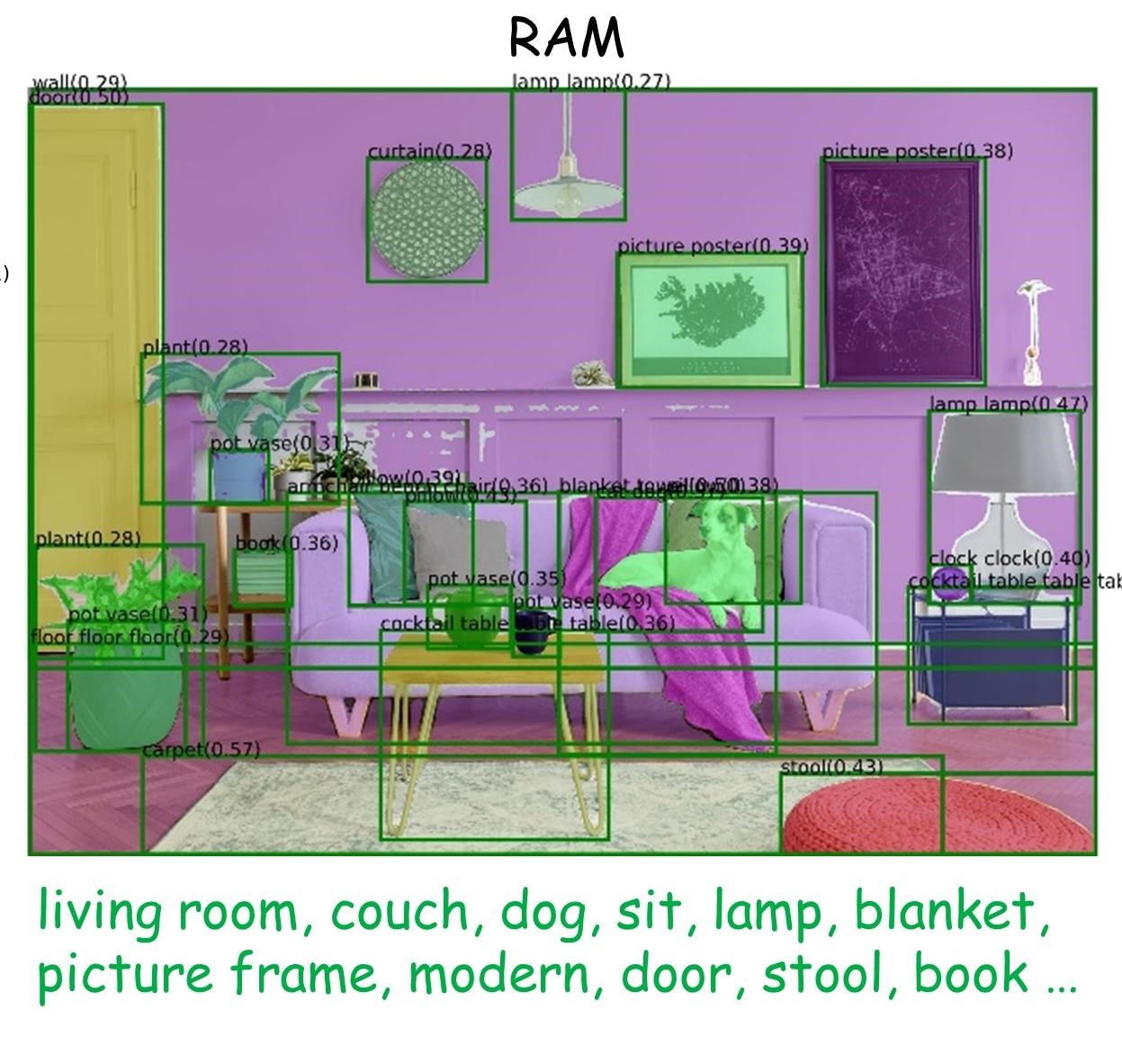
Recognizes and identifies objects, text, and other elements in images, returning structured information about detected i...

Generates text captions describing the content of images using an attention-based neural network trained on the Flickr8k...
Answer questions about images from an image and a text prompt, returning text. Generate captions, short answers, and exp...
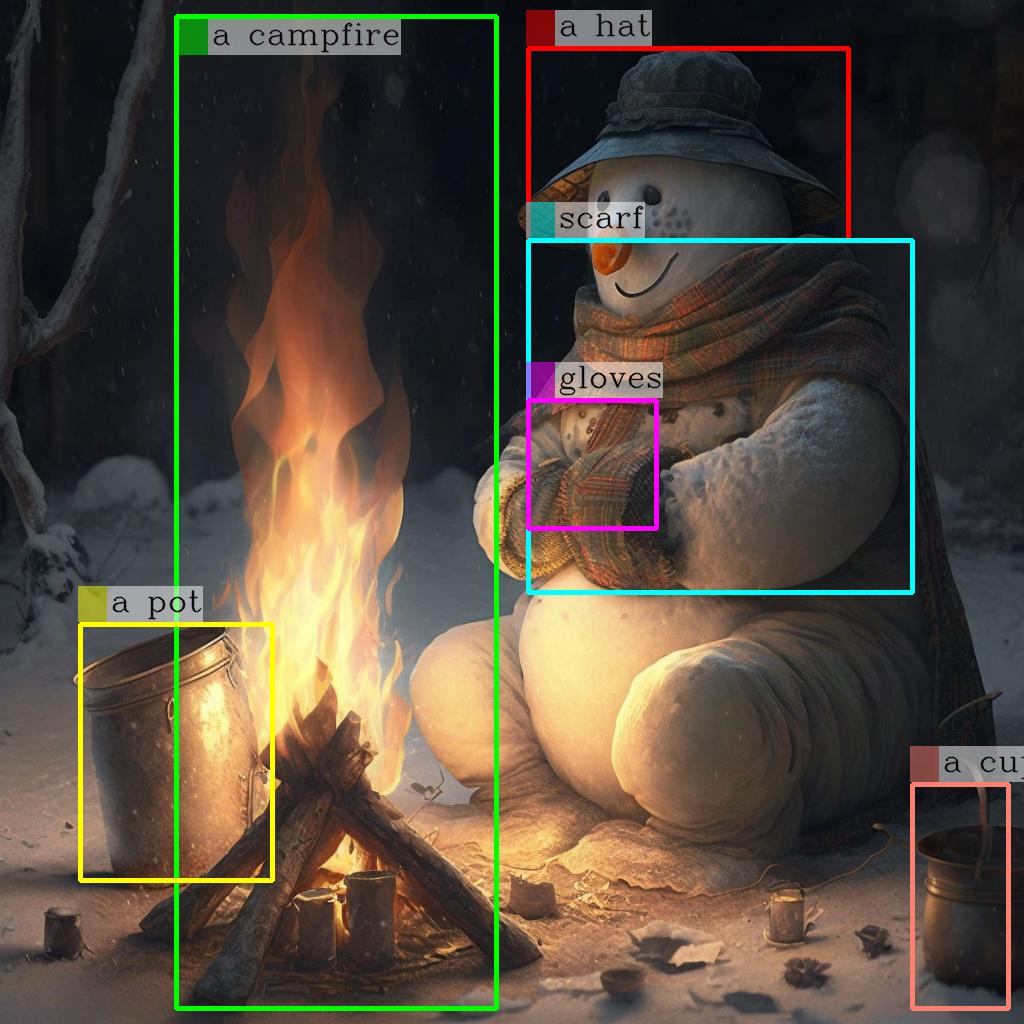
Caption images with grounded object localization. Take an image as input and return a brief or detailed natural-language...
Performs multiple computer vision tasks on images including captioning, object detection, OCR, and segmentation. Takes a...

Convert images or PDFs containing mathematical notation into Markdown/LaTeX text. Accept an image input and return a tex...
Analyzes images and answers questions or generates captions based on textual prompts. Provides six specialized models tr...

Caption images and answer visual questions from a text prompt and optional image, returning text. Support long-context i...

Tag and segment objects in images, returning labels, bounding boxes, and pixel masks. Accepts an image as input and outp...

Analyze images and answer questions about visual content using a Mixture-of-Experts vision-language model. Takes an imag...

Analyze images and answer questions about visual content using a Mixture-of-Experts vision-language model. Processes sin...

Answer questions about images and text with multimodal reasoning. Takes a text prompt with an optional image and outputs...

Analyzes images and generates text descriptions or responses to prompts about visual content. Processes diverse image ty...

Caption images. Takes a single image as input and returns a concise natural-language description of the scene, objects,...

Classify 37 dog and cat breeds from an input image, returning the predicted breed label. Uses a fine-tuned ResNet18 for...